

Прямоугольный код
Прямоугольный код, называемый также композиционным, можно представить в виде параллельной структуры кода, изображенной на рис. 6.8, б. Код создается следующим образом. Вначале из битов сообщения строятся прямоугольники, состоящие из М строк и N столбцов; затем к каждой строке и каждому столбцу прибавляется бит четности, что в результате дает матрицу размером (М+ 1) х (N+ 1). Степень кодирования прямоугольного кода, k/n, может быть записана следующим образом.
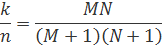
Насколько прямоугольный код мощнее кода, который имеет один контрольный бит и предоставляет только возможность обнаружить ошибку? Отметим, что любая отдельная ошибка в разряде приведет к нарушению четности в одном столбце и в одной из строк матрицы. Следовательно, прямоугольный код может исправить любую единичную ошибку, поскольку расположение такой ошибки однозначно определяется пересечением строки и столбца, в которых была нарушена четность. В примере, показанном на рис. 6.8, б, размеры матрицы равны М= N = 5; следовательно, на рисунке отображен код (36, 25), способный исправлять единичные ошибки, расположенные, в любом из 36 двоичных разрядов. Вычислим для такого блочного кода с коррекцией ошибок вероятность появления неисправленной ошибки, для чего учтем все способы появления ошибки сообщения. Исходя из вероятности наличия j ошибок в блоке из п символов, записанной в выражении (6.5), можно записать вероятность ошибки сообщения, называемой также блочной ошибкой или ошибочным словом, для кода, который может исправить ошибочные комбинации, состоящие из t или менее ошибочных битов.
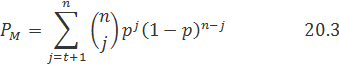
Здесь р — вероятность получения ошибочного канального символа. В примере на рис. 20.1, б код может исправить все однобитовые ошибки (t = 1) в прямоугольном блоке, состоящем из n = 36 бит. Следовательно, суммирование в уравнении (20.3) начинается с j = 2.
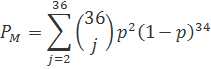
При достаточно малом р, наибольший вклад дает первое слагаемое суммы. Следовательно, для примера с прямоугольным кодом (36, 25) можно записать следующее.
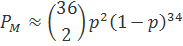
Точная вероятность битовой ошибки
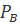
зависит от конкретного кода и используемого декодера.

Чтобы устранить ошибки передачи, вносимые атмосферой Земли (слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется на компакт-дисках и DVD. К типичным ошибкам относятся недостающие пиксели (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
В теории информации и теории кодирования с приложениями в информатике и связи , обнаружения и коррекции ошибок или защиты от ошибок методы , которые дают возможность надежной доставки из цифровых данных по ненадежным каналам связи . Многие каналы связи подвержены канальному шуму , поэтому при передаче от источника к приемнику могут возникать ошибки. Методы обнаружения ошибок позволяют обнаруживать такие ошибки, а исправление ошибок во многих случаях позволяет восстановить исходные данные.
Обнаружение ошибок – это обнаружение ошибок, вызванных шумом или другими помехами во время передачи от передатчика к приемнику.
Исправление ошибок – это обнаружение ошибок и восстановление исходных безошибочных данных.
Современная разработка кодов исправления ошибок приписывается Ричарду Хэммингу в 1947 году. Описание кода Хэмминга появилось в « Математической теории коммуникации» Клода Шеннона и было быстро обобщено
Все схемы обнаружения и исправления ошибок добавляют к сообщению некоторую избыточность (т. Е. Некоторые дополнительные данные), которые получатели могут использовать для проверки согласованности доставленного сообщения и для восстановления данных, которые были определены как поврежденные. Схемы обнаружения и исправления ошибок могут быть систематическими или несистематическими. В систематической схеме передатчик отправляет исходные данные и присоединяет фиксированное количество контрольных битов (или данных четности ), которые выводятся из битов данных с помощью некоторого детерминированного алгоритма . Если требуется только обнаружение ошибок, приемник может просто применить тот же алгоритм к полученным битам данных и сравнить свой вывод с полученными контрольными битами; если значения не совпадают, в какой-то момент во время передачи произошла ошибка. В системе, которая использует несистематический код, исходное сообщение преобразуется в закодированное сообщение, несущее ту же информацию и имеющее, по крайней мере, столько же битов, сколько и исходное сообщение.
Хорошая эффективность контроля ошибок требует, чтобы схема выбиралась на основе характеристик канала связи. Общие модели каналов включают без памяти, в которых ошибки возникают случайным образом и с определенной вероятностью, и динамические модели, в которых ошибки возникают в основном пакетами . Следовательно, ошибки обнаружения и исправления коды могут быть в общем различие между случайным-обнаружения ошибок / коррекции и пакеты ошибок обнаружения / коррекции . Некоторые коды могут также подходить для сочетания случайных ошибок и пакетных ошибок.
Если характеристики канала не могут быть определены или сильно изменяются, схема обнаружения ошибок может быть объединена с системой для повторных передач ошибочных данных. Это называется автоматическим запросом на повторение (ARQ) и чаще всего используется в Интернете. Альтернативный подход к контролю ошибок – это гибридный автоматический запрос на повторение (HARQ), который представляет собой комбинацию ARQ и кодирования с исправлением ошибок.
Виды исправления ошибок
Есть три основных типа исправления ошибок.
Автоматический повторный запрос (ARQ)
Автоматический запрос на повторение (ARQ) – это метод контроля ошибок для передачи данных, который использует коды обнаружения ошибок, сообщения подтверждения и / или отрицательного подтверждения, а также тайм-ауты для достижения надежной передачи данных. Подтверждение является сообщение , отправленное приемником , чтобы указать , что он правильно получил фрейм данных .
Обычно, когда передатчик не получает подтверждения до истечения тайм-аута (т. Е. В течение разумного промежутка времени после отправки кадра данных), он повторно передает кадр до тех пор, пока он либо не будет принят правильно, либо ошибка не останется за пределами заранее определенного количества повторных передач. .
Три типа протоколов ARQ являются Stop и ждать ARQ , Go-Back-N ARQ и Selective Repeat ARQ .
ARQ подходит, если канал связи имеет переменную или неизвестную пропускную способность , например, в случае с Интернетом. Однако ARQ требует наличия обратного канала , что приводит к возможному увеличению задержки из-за повторных передач и требует обслуживания буферов и таймеров для повторных передач, что в случае перегрузки сети может создать нагрузку на сервер и общую пропускную способность сети.
Например, ARQ используется на коротковолновых линиях радиосвязи в форме ARQ-E или в сочетании с мультиплексированием как ARQ-M .
Прямое исправление ошибок
Прямое исправление ошибок (FEC) – это процесс добавления избыточных данных, таких как код исправления ошибок (ECC), в сообщение, чтобы получатель мог его восстановить, даже если количество ошибок used) были введены либо в процессе передачи, либо при хранении. Поскольку получатель не должен запрашивать у отправителя повторную передачу данных, обратный канал не требуется для прямого исправления ошибок, и поэтому он подходит для симплексной связи, такой как широковещательная передача . Коды с исправлением ошибок часто используются в коммуникациях нижнего уровня , а также для надежного хранения на таких носителях, как компакт-диски , DVD-диски , жесткие диски и ОЗУ .
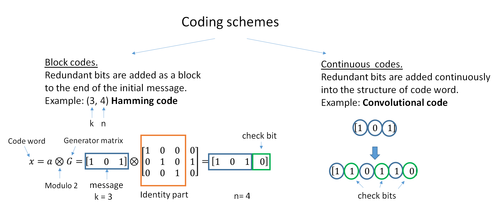
Коды с исправлением ошибок обычно различают сверточные коды и блочные коды :
Теорема Шеннона является важной теоремой прямого исправления ошибок и описывает максимальную скорость передачи информации, при которой возможна надежная связь по каналу с определенной вероятностью ошибки или отношением сигнал / шум (SNR). Этот строгий верхний предел выражается в пропускной способности канала . Более конкретно, теорема говорит, что существуют коды, такие, что с увеличением длины кодирования вероятность ошибки на дискретном канале без памяти может быть сделана сколь угодно малой при условии, что скорость кода меньше, чем пропускная способность канала. Кодовая скорость определяется как доля k / n из k исходных символов и n кодированных символов.
Фактическая максимальная разрешенная кодовая скорость зависит от используемого кода исправления ошибок и может быть ниже. Это связано с тем, что доказательство Шеннона носило исключительно экзистенциальный характер и не показало, как создавать коды, которые одновременно являются оптимальными и имеют эффективные алгоритмы кодирования и декодирования.
Гибридный ARQ – это комбинация ARQ и прямого исправления ошибок. Есть два основных подхода:
Последний подход особенно привлекателен для канала стирания при использовании бесскоростного кода стирания .
Схемы обнаружения ошибок
Обнаружение ошибок чаще всего реализуется с использованием подходящей хеш-функции (или, в частности, контрольной суммы , проверки циклическим избыточным кодом или другого алгоритма). Хеш-функция добавляет к сообщению тег фиксированной длины , который позволяет получателям проверять доставленное сообщение, повторно вычисляя тег и сравнивая его с предоставленным.
Существует огромное количество различных конструкций хеш-функций. Однако некоторые из них имеют особенно широкое распространение из-за их простоты или их пригодности для обнаружения определенных видов ошибок (например, производительности циклического контроля избыточности при обнаружении пакетных ошибок ).
Кодирование минимального расстояния
Код с исправлением случайных ошибок, основанный на кодировании с может обеспечить строгую гарантию количества обнаруживаемых ошибок, но не может защитить от атаки по прообразу .
Код с повторением является схемой кодирования , которая повторяет биты по каналу для достижения безошибочной связи. Учитывая поток данных, которые необходимо передать, данные делятся на блоки битов. Каждый блок передается определенное количество раз. Например, чтобы отправить битовую комбинацию «1011», четырехбитовый блок можно повторить три раза, таким образом получая «1011 1011 1011». Если этот двенадцатибитовый шаблон был получен как «1010 1011 1011» – где первый блок не похож на два других, – произошла ошибка.
Код повторения очень неэффективен и может быть подвержен проблемам, если ошибка возникает точно в одном и том же месте для каждой группы (например, «1010 1010 1010» в предыдущем примере будет обнаружено как правильное). Преимущество кодов повторения состоит в том, что они чрезвычайно просты и фактически используются в некоторых передачах цифровых станций .
Бит четности является бит , который добавляется к группе исходных битов , чтобы гарантировать , что количество установленных битов (то есть, биты со значением 1) в исходе четным или нечетным. Это очень простая схема, которую можно использовать для обнаружения одиночного или любого другого нечетного числа (т. Е. Трех, пяти и т. Д.) Ошибок в выходных данных. Четное количество перевернутых битов сделает бит четности правильным, даже если данные ошибочны.
Биты четности, добавляемые к каждому отправляемому «слову», называются проверками поперечным избыточным кодом , а биты , добавленные в конце потока «слов», называются проверками продольного избыточного кода . Например, если к каждому из серии m-битовых «слов» добавлен бит четности, показывающий, было ли в этом слове нечетное или четное количество единиц, будет обнаружено любое слово с единственной ошибкой в нем. Однако неизвестно, в каком месте слова находится ошибка. Если, кроме того, после каждого потока из n слов отправляется сумма четности, каждый бит которой показывает, было ли нечетное или четное количество единиц в этой битовой позиции, отправленной в самой последней группе, точная позиция ошибки можно определить и исправить ошибку. Однако эффективность этого метода гарантируется только в том случае, если в каждой группе из n слов не более 1 ошибки. Чем больше битов исправления ошибок, тем больше ошибок может быть обнаружено и в некоторых случаях исправлено.
Существуют также другие методы группировки битов.
Контрольная сумма сообщения – это модульная арифметическая сумма кодовых слов сообщения фиксированной длины слова (например, байтовых значений). Сумма может быть инвертирована посредством операции дополнения до перед передачей для обнаружения непреднамеренных сообщений с нулевым значением.
Схемы контрольных сумм включают в себя биты четности, контрольные цифры и проверки продольной избыточности . Некоторые схемы контрольных сумм, такие как Даммы алгоритм , в алгоритме Лун , и алгоритм верхуфф , специально предназначены для обнаружения ошибок , обычно вносимых человеком в написании или запоминании идентификационных номеров.
Циклическая проверка избыточности
Циклический избыточный код (CRC) представляет собой незащищенное хэш – функция предназначена для обнаружения случайных изменений цифровых данных в компьютерных сетях. Он не подходит для обнаружения злонамеренно внесенных ошибок. Он характеризуется указанием порождающего полинома , который используется в качестве делителя при полиномиальном делении на конечное поле , принимая входные данные в качестве делимого . Остальное становится результатом.
У CRC есть свойства, которые делают его хорошо подходящим для обнаружения пакетных ошибок . CRC особенно легко реализовать на оборудовании и поэтому обычно используются в компьютерных сетях и устройствах хранения, таких как жесткие диски .
Бит четности можно рассматривать как 1-битную CRC особого случая.
Выходные данные криптографической хеш-функции , также известной как дайджест сообщения , могут обеспечить строгие гарантии целостности данных , независимо от того, были ли изменения данных случайными (например, из-за ошибок передачи) или внесены злонамеренно. Любое изменение данных, вероятно, будет обнаружено по несоответствию хеш-значения. Кроме того, с учетом некоторого значения хеш-функции обычно невозможно найти некоторые входные данные (кроме заданных), которые дадут такое же значение хеш-функции. Если злоумышленник может изменить не только сообщение, но и значение хеш-функции, то для дополнительной безопасности можно использовать хэш- код с код аутентификации сообщения (MAC). Не зная ключа, злоумышленник не может легко или удобно вычислить правильное ключевое значение хеш-функции для измененного сообщения.
Код исправления ошибок
Для обнаружения ошибок можно использовать любой код исправления ошибок. Код с минимальным расстоянием Хэмминга , d , может обнаруживать до d – 1 ошибок в кодовом слове. Использование кодов с коррекцией ошибок на основе минимального расстояния для обнаружения ошибок может быть подходящим, если требуется строгое ограничение на минимальное количество обнаруживаемых ошибок.
Коды с минимальным расстоянием Хэмминга d = 2 являются вырожденными случаями кодов с исправлением ошибок и могут использоваться для обнаружения одиночных ошибок. Бит четности является примером кода обнаружения одиночной ошибки.
Приложения, которым требуется низкая задержка (например, телефонные разговоры), не могут использовать автоматический запрос на повторение (ARQ); они должны использовать прямое исправление ошибок (FEC). К тому времени, когда система ARQ обнаружит ошибку и повторно передаст ее, повторно отправленные данные прибудут слишком поздно, чтобы их можно было использовать.
Приложения, в которых передатчик сразу же забывает информацию, как только она отправляется (например, большинство телекамер), не могут использовать ARQ; они должны использовать FEC, потому что при возникновении ошибки исходные данные больше не доступны.
Приложения, использующие ARQ, должны иметь обратный канал ; приложения, не имеющие обратного канала, не могут использовать ARQ.
Приложения, требующие крайне низкого уровня ошибок (например, цифровые денежные переводы), должны использовать ARQ из-за возможности неисправимых ошибок с помощью FEC.
Техника обеспечения надежности и контроля также использует теорию кодов с исправлением ошибок.
В типичном стеке TCP / IP контроль ошибок выполняется на нескольких уровнях:
Телекоммуникации в дальнем космосе
Разработка кодов исправления ошибок была тесно связана с историей полетов в дальний космос из-за чрезмерного ослабления мощности сигнала на межпланетных расстояниях и ограниченной доступной мощности на борту космических зондов. В то время как ранние миссии отправляли свои данные в незашифрованном виде, начиная с 1968 года, цифровая коррекция ошибок была реализована в форме (субоптимально декодированных) сверточных кодов и Рида-Мюллера . Код Рида-Мюллера хорошо подходил к шуму, которому подвергался космический корабль (приблизительно соответствуя колоколообразной кривой ), и был реализован для космического корабля Mariner и использовался в миссиях между 1969 и 1977 годами.
В Voyager 1 и Voyager 2 миссии, которая началась в 1977 году, были разработаны , чтобы обеспечить цветное изображение и научную информацию от Юпитера и Сатурна . Это привело к увеличению требований к кодированию, и, таким образом, космический аппарат поддерживался (оптимально декодированным по Витерби ) сверточными кодами, которые можно было объединить с внешним кодом Голея (24,12,8) . Корабль “Вояджер-2” дополнительно поддерживал реализацию кода Рида-Соломона . Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну . После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
Консультативный комитет по системам космических данных в настоящее время рекомендует использование кодов коррекции ошибок с производительностью аналогична кодой RSV Voyager 2 как минимум. Составные коды все больше теряют популярность в космических полетах и заменяются более мощными кодами, такими как турбокоды или коды LDPC .
Различные виды выполняемых миссий в дальний космос и орбитальные полеты предполагают, что попытка найти универсальную систему исправления ошибок будет постоянной проблемой. Для миссий, близких к Земле, характер шума в канале связи отличается от того, который испытывает космический корабль во время межпланетной миссии. Кроме того, по мере того, как космический корабль удаляется от Земли, проблема коррекции шума становится все более сложной.
Спрос на пропускную способность спутникового ретранслятора продолжает расти, чему способствует желание предоставлять телевидение (включая новые каналы и телевидение высокой четкости ) и данные IP. Доступность транспондеров и ограничения полосы пропускания ограничили этот рост. Пропускная способность транспондера определяется выбранной схемой модуляции и долей пропускной способности, потребляемой FEC.
Коды обнаружения и исправления ошибок часто используются для повышения надежности носителей данных. Дорожка четности, способная обнаруживать однобитовые ошибки, присутствовала в первом хранилище данных на в 1951 году. Оптимальный прямоугольный код, используемый в записывающих лентах с не только обнаруживает, но и исправляет однобитовые ошибки. Некоторые форматы файлов , особенно форматы архивов , включают контрольную сумму (чаще всего CRC32 ) для обнаружения повреждения и усечения и могут использовать файлы избыточности или для восстановления частей поврежденных данных. Коды Рида-Соломона используются в компакт-дисках для исправления ошибок, вызванных царапинами.
Современные жесткие диски используют коды Рида-Соломона для обнаружения исправления незначительных ошибок при чтении секторов, а также для восстановления поврежденных данных из неисправных секторов и сохранения этих данных в резервных секторах. В системах используются различные методы исправления ошибок для восстановления данных при полном отказе жесткого диска. системы, такие как ZFS или Btrfs , а также некоторые реализации RAID поддерживают очистку данных и повторное обновление, что позволяет обнаруживать и (надеюсь) восстанавливать плохие блоки перед их использованием. Восстановленные данные могут быть перезаписаны точно в том же физическом месте, чтобы освободить блоки в другом месте на том же оборудовании, или данные могут быть перезаписаны на заменяющем оборудовании.
Память с исправлением ошибок
Динамическая память с произвольным доступом (DRAM) может обеспечить более надежную защиту от мягких ошибок , полагаясь на коды исправления ошибок. Такая память с исправлением ошибок, известная как память с ECC или EDAC , особенно желательна для критически важных приложений, таких как научные вычисления, финансы, медицина и т. Д., А также для внеземных приложений из-за повышенной радиации в космосе.
Контроллеры памяти с исправлением ошибок традиционно используют коды Хэмминга , хотя некоторые используют тройное модульное резервирование . Чередование позволяет распределить эффект одного космического луча, потенциально нарушающего несколько физически соседних битов по нескольким словам, путем связывания соседних битов с разными словами. До тех пор, пока нарушение единичного события (SEU) не превышает пороговое значение ошибки (например, одиночная ошибка) в любом конкретном слове между доступами, оно может быть исправлено (например, с помощью однобитового кода исправления ошибок), и иллюзия безошибочной системы памяти может сохраняться.
В дополнение к аппаратным средствам, обеспечивающим функции, необходимые для работы памяти ECC, операционные системы обычно содержат соответствующие средства отчетности, которые используются для предоставления уведомлений при прозрачном восстановлении программных ошибок. Одним из примеров является подсистема ядра Linux (ранее известная как ), которая собирает данные из компонентов компьютерной системы с включенной функцией проверки ошибок; Помимо сбора и отправки отчетов о событиях, связанных с памятью ECC, он также поддерживает другие ошибки контрольной суммы, в том числе обнаруженные на . Некоторые системы также поддерживают для выявления и исправления ошибок на раннем этапе, прежде чем они станут неисправимыми.
схема управления ошибками в данных по зашумленным каналам связи
В вычислениях, телекоммуникации, теория информации и теория кодирования, код исправления ошибок, иногда код исправления ошибок, (ECC ) используется для контроля ошибок в данных по ненадежным или зашумленным каналам связи. Основная идея заключается в том, что отправитель кодирует сообщение с помощью избыточной информации в форме ECC. Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникать в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. Американский математик Ричард Хэмминг был пионером в этой области в 1940-х годах и изобрел первый исправляющий ошибки код в 1950 году: код Хэмминга (7,4).
ECC контрастирует с обнаружением ошибок. в том, что обнаруженные ошибки можно исправить, а не просто обнаружить. Преимущество состоит в том, что системе, использующей ECC, не требуется обратный канал для запроса повторной передачи данных при возникновении ошибки. Обратной стороной является то, что к сообщению добавляются фиксированные накладные расходы, что требует более высокой полосы пропускания прямого канала. Таким образом, ECC применяется в ситуациях, когда повторные передачи являются дорогостоящими или невозможными, например, при односторонних каналах связи и при передаче на несколько приемников в многоадресной передаче. Соединения с длительной задержкой также выигрывают; в случае спутника, вращающегося вокруг Урана, повторная передача из-за ошибок может вызвать задержку в пять часов. Информация ECC обычно добавляется к запоминающим устройствам для восстановления поврежденных данных, широко используется в модемах и используется в системах, где основной памятью является память ECC.
Обработка ЕСС в приемнике может применяться к цифровому потоку битов или к демодуляции несущей с цифровой модуляцией. В последнем случае ECC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала, искаженного шумом. Многие кодеры / декодеры ECC также могут генерировать сигнал с коэффициентом ошибок по битам (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой приемной электроники.
Максимальная доля ошибок или отсутствующих битов, которые могут быть исправлены, определяется конструкцией кода ECC, поэтому разные коды исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Теорема кодирования с шумом канала из Клод Шеннон отвечает на вопрос о том, какая полоса пропускания остается для передачи данных при использовании наиболее эффективного кода, который сводит вероятность ошибки декодирования к нулю. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Однако это доказательство неконструктивно и, следовательно, не дает представления о том, как создать код, обеспечивающий производительность. После многих лет исследований некоторые современные системы ECC сегодня очень близки к теоретическому максимуму.
В электросвязи, теории информации и теории кодирования, прямое исправление ошибок (FEC ) или канальное кодирование – это метод, используемый для контроля ошибок в передаче данных по ненадежным или зашумленным каналам связи. Основная идея заключается в том, что отправитель кодирует сообщение с помощью избыточного способа, чаще всего с помощью ECC.
Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникнуть в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. FEC дает приемнику возможность исправлять ошибки без необходимости использования обратного канала для запроса повторной передачи данных, но за счет фиксированной более высокой полосы пропускания прямого канала. Поэтому FEC применяется в ситуациях, когда повторные передачи являются дорогостоящими или невозможными, например, при односторонних каналах связи и при передаче на несколько приемников в многоадресной передаче. Информация FEC обычно добавляется к запоминающим устройствам (магнитным, оптическим и твердотельным / флэш-накопителям) для восстановления поврежденных данных, широко используется в модемах, используется в системах, где первичной памятью является память ECC, и в ситуациях широковещательной передачи, когда приемник не имеет возможности запрашивать повторную передачу или это может вызвать значительную задержку. Например, в случае спутника, вращающегося вокруг Урана, повторная передача из-за ошибок декодирования может вызвать задержку не менее 5 часов.
Обработка FEC в приемнике может применяться к цифровому битовому потоку или при демодуляции несущей с цифровой модуляцией. Для последнего FEC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала, искаженного шумом. Многие кодеры FEC могут также генерировать сигнал с коэффициентом ошибок по битам (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой приемной электроники.
Максимальная доля ошибок или недостающих битов, которые могут быть исправлены, определяется конструкцией ECC, поэтому разные коды прямого исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Теорема кодирования канала с шумом Клода Шеннона отвечает на вопрос о том, какая полоса пропускания остается для передачи данных при использовании наиболее эффективного кода, который обращает вероятность ошибки декодирования в ноль. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Его доказательство неконструктивно и, следовательно, не дает понимания того, как создать код, обеспечивающий производительность. Однако после многих лет исследований некоторые передовые системы FEC, такие как полярный код, достигают пропускной способности канала Шеннона при гипотезе кадра бесконечной длины.
Как это работает
ECC достигается путем добавления избыточности к передаваемой информации с использованием алгоритма. Избыточный бит может быть сложной функцией многих исходных информационных битов. Исходная информация может появляться или не появляться буквально в закодированном выводе; коды, которые включают немодифицированный ввод в вывод, являются систематическими, тогда как те, которые не включают, являются несистематическими .
Упрощенный пример ECC – передача каждого бита данных 3 раза, что известно как код повторения (3,1) . Через шумный канал приемник может видеть 8 вариантов вывода, см. Таблицу ниже.
Это позволяет исправить ошибку в любой из трех выборок «большинством голосов» или «демократическим голосованием». Корректирующая способность этого ECC:
Хотя прост в реализации и Это широко используемое тройное модульное резервирование является относительно неэффективным ECC. Более совершенные коды ECC обычно проверяют несколько последних десятков или даже несколько последних сотен ранее принятых битов, чтобы определить, как декодировать текущую небольшую группу битов (обычно в группах от 2 до 8 бит).
Усреднение шума для уменьшения ошибок
Можно сказать, что ECC работает посредством «усреднения шума»; поскольку каждый бит данных влияет на многие передаваемые символы, искажение одних символов шумом обычно позволяет извлекать исходные пользовательские данные из других неповрежденных принятых символов, которые также зависят от тех же пользовательских данных.
Большинство телекоммуникационных систем используют фиксированный канальный код, рассчитанный на ожидаемый наихудший случай частоты ошибок по битам, а затем вообще не работают если частота ошибок по битам станет еще хуже. Однако некоторые системы адаптируются к данным условиям ошибки канала: некоторые экземпляры гибридного автоматического запроса на повторение используют фиксированный метод ECC, пока ECC может обрабатывать частоту ошибок, затем переключаются на ARQ когда частота ошибок становится слишком высокой; адаптивная модуляция и кодирование использует различные скорости ECC, добавляя больше битов исправления ошибок на пакет, когда в канале более высокие частоты ошибок, или удаляя их, когда они не нужны.
Типы ECC
Краткая классификация кодов коррекции ошибок.
Двумя основными категориями кодов ECC являются блочные коды и сверточные коды.
Существует много типов блочных кодов; Кодирование Рида-Соломона примечательно тем, что оно широко используется в компакт-дисках, DVD и жестких дисках. Другие примеры классических блочных кодов включают Голея, BCH, многомерную четность и коды Хэмминга.
ECC Хэмминга обычно используются для исправления NAND flash ошибки памяти. Это обеспечивает исправление однобитовых ошибок и обнаружение двухбитовых ошибок. Коды Хэмминга подходят только для более надежной одноуровневой ячейки (SLC) NAND. Более плотная многоуровневая ячейка (MLC) NAND может использовать многобитовый корректирующий ECC, такой как BCH или Reed-Solomon. NOR Flash обычно не использует никакого исправления ошибок.
Классические блочные коды обычно декодируются с использованием алгоритмов жесткого решения, что означает, что для каждого входного и выходного сигнала принимается жесткое решение, будет ли он соответствует единице или нулю бит. Напротив, сверточные коды обычно декодируются с использованием алгоритмов мягкого решения, таких как алгоритмы Витерби, MAP или BCJR, которые обрабатывают (дискретизированные) аналоговые сигналы и которые допускают гораздо более высокие ошибки – производительность коррекции, чем декодирование с жестким решением.
Почти все классические блочные коды применяют алгебраические свойства конечных полей. Поэтому классические блочные коды часто называют алгебраическими кодами.
В отличие от классических блочных кодов, которые часто определяют способность обнаружения или исправления ошибок, многие современные блочные коды, такие как коды LDPC, не имеют таких гарантий. Вместо этого современные коды оцениваются с точки зрения их частоты ошибок по битам.
Большинство кодов прямого исправления ошибок исправляют только перевороты битов, но не вставки или удаления битов. В этой настройке расстояние Хэмминга является подходящим способом измерения коэффициента битовых ошибок. Несколько кодов прямого исправления ошибок предназначены для исправления вставки и удаления битов, например, коды маркеров и коды водяных знаков. Расстояние Левенштейна является более подходящим способом измерения частоты ошибок по битам при использовании таких кодов.
Кодовая скорость и компромисс между надежностью и скоростью передачи данных
Фундаментальный принцип ECC состоит в добавлении избыточных битов, чтобы помочь декодеру узнать истинное сообщение, которое было закодировано передатчик. Кодовая скорость данной системы ЕСС определяется как соотношение между количеством информационных битов и общим количеством битов (то есть информацией плюс биты избыточности) в данном коммуникационном пакете. Кодовая скорость, следовательно, является действительным числом. Низкая кодовая скорость, близкая к нулю, подразумевает сильный код, который использует много избыточных битов для достижения хорошей производительности, в то время как большая кодовая скорость, близкая к 1, подразумевает слабый код.
Избыточные биты, защищающие информацию, должны передаваться с использованием тех же коммуникационных ресурсов, которые они пытаются защитить. Это вызывает фундаментальный компромисс между надежностью и скоростью передачи данных. В одном крайнем случае сильный код (с низкой кодовой скоростью) может вызвать значительное увеличение SNR приемника (отношение сигнал / шум), уменьшая частоту ошибок по битам, за счет снижения эффективной скорости передачи данных. С другой стороны, без использования какого-либо ECC (то есть кодовой скорости, равной 1) используется полный канал для целей передачи информации за счет того, что биты остаются без какой-либо дополнительной защиты.
Один интересный вопрос заключается в следующем: насколько эффективным с точки зрения передачи информации может быть ECC, имеющий незначительную частоту ошибок декодирования? На этот вопрос ответил Клод Шеннон с его второй теоремой, которая гласит, что пропускная способность канала – это максимальная скорость передачи данных, достижимая для любого ECC, частота ошибок которого стремится к нулю: его доказательство основано на гауссовском случайном кодировании, которое не подходит для реального мира. Приложения. Верхняя граница, заданная работой Шеннона, вдохновила на долгий путь к разработке ECC, которые могут приблизиться к пределу конечных характеристик. Различные коды сегодня могут достигать почти предела Шеннона. Однако ECC, обеспечивающие пропускную способность, обычно чрезвычайно сложно реализовать.
Наиболее популярные ECC имеют компромисс между производительностью и вычислительной сложностью. Обычно их параметры дают диапазон возможных кодовых скоростей, которые можно оптимизировать в зависимости от сценария. Обычно эта оптимизация выполняется для достижения низкой вероятности ошибки декодирования при минимальном влиянии на скорость передачи данных. Другим критерием оптимизации кодовой скорости является уравновешивание низкой частоты ошибок и количества повторных передач с учетом энергетических затрат на связь.
Составные коды ECC для повышения производительности
Классические (алгебраические) блочные коды а сверточные коды часто комбинируются в схемах конкатенированного кодирования, в которых сверточный код, декодированный по Витерби с короткой ограниченной длиной, выполняет большую часть работы, а блочный код (обычно Рида-Соломона) с большим размером символа и длиной блока «стирает» любые ошибки, сделанные сверточным декодером. Однопроходное декодирование с использованием этого семейства кодов с исправлением ошибок может дать очень низкий уровень ошибок, но для условий передачи на большие расстояния (например, в глубоком космосе) рекомендуется итеративное декодирование.
Составные коды были стандартной практикой в спутниковой связи и связи в дальнем космосе с тех пор, как “Вояджер-2 ” впервые применил эту технику во время встречи с Ураном в 1986 году. Аппарат Galileo использовал итеративные конкатенированные коды для компенсации условий очень высокой частоты ошибок, вызванных отказом антенны.
Проверка на четность с низкой плотностью (LDPC)
Коды с проверкой на четность с низкой плотностью (LDPC) – это класс высокоэффективных линейных блочных кодов, созданных из множества кодов одиночной проверки на четность (SPC). Они могут обеспечить производительность, очень близкую к пропускной способности канала (теоретический максимум), используя подход итеративного декодирования с мягким решением, при линейной временной сложности с точки зрения длины их блока. Практические реализации в значительной степени полагаются на параллельное декодирование составляющих кодов SPC.
Коды LDPC были впервые введены Робертом Г. Галлагером в его докторской диссертации в 1960 году, но из-за вычислительных усилий при реализации кодера и декодера и введения Рида-Соломона коды, они в основном игнорировались до 1990-х годов.
Коды LDPC теперь используются во многих недавних стандартах высокоскоростной связи, таких как DVB-S2 (цифровое видеовещание – спутниковое – второе поколение), WiMAX ( стандарт IEEE 802.16e для микроволновой связи), высокоскоростная беспроводная локальная сеть (IEEE 802.11n ), 10GBase-T Ethernet (802.3an) и G.hn/G.9960 (Стандарт ITU-T для организации сетей по линиям электропередач, телефонным линиям и коаксиальному кабелю). Другие коды LDPC стандартизированы для стандартов беспроводной связи в пределах 3GPP MBMS (см. исходные коды ).
Турбокоды
Турбокодирование – это схема повторяющегося мягкого декодирования, которая объединяет два или более относительно простых сверточных кода и перемежитель для создания блочного кода, который может работать с точностью до долей децибела. предела Шеннона. Предшествующие LDPC-коды с точки зрения практического применения, теперь они обеспечивают аналогичную производительность.
Одним из первых коммерческих приложений турбо-кодирования была технология цифровой сотовой связи CDMA2000 1x (TIA IS-2000), разработанная Qualcomm и продаваемая Verizon Беспроводная связь, Sprint и другие операторы связи. Он также используется для развития CDMA2000 1x специально для доступа в Интернет, 1xEV-DO (TIA IS-856). Как и 1x, EV-DO был разработан Qualcomm и продается Verizon Wireless, Sprint и другими операторами (маркетинговое название Verizon для 1xEV-DO – Широкополосный доступ, потребительские и бизнес-маркетинговые названия компании Sprint для 1xEV-DO – Power Vision и Mobile Broadband соответственно).
Локальное декодирование и тестирование кодов
Иногда необходимо декодировать только отдельные биты сообщения или проверить, является ли данный сигнал кодовым словом, и делать это, не глядя на все сигнал. Это может иметь смысл в настройке потоковой передачи, где кодовые слова слишком велики для того, чтобы их можно было классически декодировать достаточно быстро, и где на данный момент интересны только несколько битов сообщения. Также такие коды стали важным инструментом в теории сложности вычислений, например, для разработки вероятностно проверяемых доказательств.
Локально декодируемые коды являются кодами с исправлением ошибок, для которых отдельные биты сообщение может быть восстановлено вероятностно, если посмотреть только на небольшое (скажем, постоянное) количество позиций кодового слова, даже после того, как кодовое слово было искажено на некоторой постоянной доле позиций. Локально тестируемые коды – это коды с исправлением ошибок, для которых можно вероятностно проверить, близок ли сигнал к кодовому слову, посмотрев только на небольшое количество позиций сигнала.
Чередование

Краткая иллюстрация идеи чередования.
Чередование часто используется в системах цифровой связи и хранения для повышения производительности кодов прямого исправления ошибок. Многие каналы связи не лишены памяти: ошибки обычно возникают в пакетах, а не независимо друг от друга. Если количество ошибок в кодовом слове превышает возможности кода исправления ошибок, ему не удается восстановить исходное кодовое слово. Чередование облегчает эту проблему путем перетасовки исходных символов по нескольким кодовым словам, тем самым создавая более равномерное распределение ошибок. Поэтому перемежение широко используется для пакетной коррекции ошибок.
. Анализ современных повторяющихся кодов, таких как турбокоды и коды LDPC, обычно предполагает независимое распределение ошибок.. Поэтому системы, использующие коды LDPC, обычно используют дополнительное перемежение символов в кодовом слове.
Для турбокодов перемежитель является неотъемлемым компонентом, и его правильная конструкция имеет решающее значение для хорошей производительности. Алгоритм итеративного декодирования работает лучше всего, когда нет коротких циклов в графе коэффициентов, который представляет декодер; перемежитель выбран, чтобы избежать коротких циклов.
Конструкции перемежителя включают:
В системах связи с несколькими несущими может использоваться перемежение по несущим для обеспечения частотного разнесения., например, для уменьшения частотно-избирательного замирания или узкополосных помех.
Пример
Передача без перемежения :
Сообщение без ошибок: aaaabbbbccccddddeeeeffffgggg Передача с пакетной ошибкой: aaaabbbbccc____deeeeffffgggg
Здесь каждая группа одинаковых букв представляет 4-битное однобитовое кодовое слово с исправлением ошибок. Кодовое слово cccc изменяется в один бит и может быть исправлено, но кодовое слово dddd изменяется в трех битах, поэтому либо оно не может быть декодировано вообще, либо может быть декодировано неправильно.
С чередованием :
“Перемежитель” перенаправляется сюда. Для оптоволоконного устройства см. Оптический перемежитель .
В вычислительной , телекоммуникационной , теории информации и теории кодирования , в код коррекции ошибок , иногда кода коррекции ошибок ( ECC ) используется для контроля ошибок в данных по ненадежным или зашумленных каналов связи . Основная идея заключается в том, что отправитель кодирует сообщение с избыточной информацией в форме ECC. Избыточность позволяет получателю обнаруживать ограниченное количество ошибок, которые могут возникнуть в любом месте сообщения, и часто исправлять эти ошибки без повторной передачи. Американский математик Ричард Хэмминг был пионером в этой области в 1940-х годах и изобрел первый исправляющий ошибки код в 1950 году: код Хэмминга (7,4) .
ECC отличается от обнаружения ошибок тем, что ошибки можно исправлять, а не просто обнаруживать. Преимущество состоит в том, что системе, использующей ECC, не требуется обратный канал для запроса повторной передачи данных при возникновении ошибки. Обратной стороной является то, что к сообщению добавляются фиксированные накладные расходы, что требует большей полосы пропускания прямого канала. Таким образом, ECC применяется в ситуациях, когда повторные передачи являются дорогостоящими или невозможными, например, при односторонних каналах связи и при многоадресной передаче на несколько приемников . Соединения с большой задержкой также выигрывают; в случае спутника, вращающегося вокруг Урана , повторная передача из-за ошибок может вызвать задержку в пять часов. Информация ECC обычно добавляется к запоминающим устройствам для восстановления поврежденных данных, широко используется в модемах и используется в системах, где первичной памятью является память ECC .
Обработка ECC в приемнике может применяться к цифровому потоку битов или при демодуляции несущей с цифровой модуляцией. Для последнего ECC является неотъемлемой частью начального аналого-цифрового преобразования в приемнике. Декодер Витерби реализует алгоритм мягкого решения для демодуляции цифровых данных из аналогового сигнала на фоне шума. Многие кодеры / декодеры ECC могут также генерировать сигнал частоты ошибок по (BER), который можно использовать в качестве обратной связи для точной настройки аналоговой принимающей электроники.
Максимальная доля ошибок или пропущенных битов, которые могут быть исправлены, определяется конструкцией кода ECC, поэтому разные коды исправления ошибок подходят для разных условий. Как правило, более сильный код вызывает большую избыточность, которую необходимо передавать с использованием доступной полосы пропускания, что снижает эффективную скорость передачи данных при одновременном улучшении принимаемого эффективного отношения сигнал / шум. Кодирования шумным канала теорема о Клода Шеннона может быть использована для вычисления максимальной достижимой пропускной способности канала связи для заданной максимальной допустимой вероятности ошибки. Это устанавливает границы теоретической максимальной скорости передачи информации канала с некоторым заданным базовым уровнем шума. Однако это доказательство неконструктивно и, следовательно, не дает представления о том, как создать код, обеспечивающий производительность. После многих лет исследований некоторые передовые системы ECC по состоянию на 2016 год очень близко подошли к теоретическому максимуму.