

Пример . Предположим, в канале связи под действием помех произошло искажение и вместо 0100101 было принято 01001(1)1.
Решение: Для обнаружения ошибки производят уже знакомые нам проверки на четность.
Первая проверка: сумма П1+П3+П5+П7 = 0+0+1+1 четна. В младший разряд номера ошибочной позиции запишем 0.
Вторая проверка: сумма П2+П3+П6+П7 = 1+0+1+1 нечетна. Во второй разряд номера ошибочной позиции запишем 1
Третья проверка: сумма П4+П5+П6+П7 = 0+1+1+1 нечетна. В третий разряд номера ошибочной позиции запишем 1. Номер ошибочной позиции 110= 6. Следовательно, символ шестой позиции следует изменить на обратный, и получим правильную кодовую комбинацию.
Код, исправляющий одиночную и обнаруживающий двойную ошибки
Если по изложенным выше правилам строить корректирующий код с обнаружением и исправлением одиночной ошибки для равномерного двоичного кода, то первые 16 кодовых комбинаций будут иметь вид, показанный в таблице. Такой код может быть использован для построения кода с исправлением одиночной ошибки и обнаружением двойной.
Для этого, кроме указанных выше проверок по контрольным позициям, следует провести еще одну проверку на четность для всей строки в целом. Чтобы осуществить такую проверку, следует к каждой строке кода добавить контрольные символы, записанные в дополнительной колонке (таблица, колонка 8). Тогда в случае одной ошибки проверки по позициям укажут номер ошибочной позиции, а проверка на четность – на наличие ошибки. Если проверки позиций укажут на наличие ошибки, а проверка на четность не фиксирует ее, значит в кодовой комбинации две ошибки.
Построение кода Хэмминга
Пример: Построить макет кода Хемминга и определить значения корректирующих разрядов для кодовой комбинации k=4, X=0101.
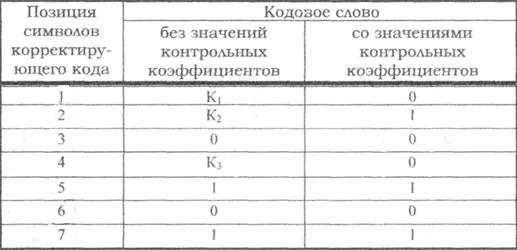
Согласно таблице минимальное число контрольных символов r=3, при этом n = 7. Контрольный коэффициенты будут расположены на позициях 1, 2, 4. Составим макет корректирующего кода и запишем его во вторую колонку таблицы. Пользуясь таблицей для номеров проверочных коэффициентов, определим значения коэффициентов К1 К2 и К3.
Первая проверка: сумма П1+П3+П5+П7 должна быть четной, а сумма К1+0+1+1 будет четной при К =0.
Вторая проверка: сумма П2+П3+П6+П7 должна быть четной, а сумма К2+0+0+1 будет четной при К2=1.
Третья проверка: сумма П4+П5+П6+П7 должна быть четной, а сумма К3+1+0+1 будет четной при К3=0.
Окончательное значение искомой комбинации корректирующего кода записываем в третью колонку таблицы макета кода.
Систематические коды представляют собой такие коды, в которых информационные и корректирующие разряды расположены по строго определенной системе и всегда занимают строго определенные места в кодовых комбинациях. Систематические коды являются равномерными, т.е. все комбинации кода с заданными корректирующими способностями имеют одинаковую длину. Групповые коды также являются систематическими, но не все систематические коды могут быть отнесены к групповым.
Код Хэмминга является типичным примером систематического кода. Однако при его построении к матрицам обычно не прибегают. Для вычисления основных параметров кода задается либо количество информационных символов, либо количество информационных комбинаций N = 2k. При помощи формул
вычисляются k и r . Соотношения между n, k и r для кода Хэмминга представлены в таблице
Таблица 5.10 – Соотношения между n, k, r в коде Хэмминга
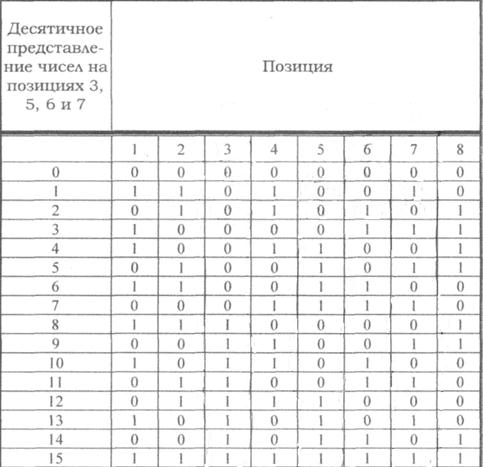
Зная основные параметры корректирующего кода, определяют: какие позиции кода будут информационными, а какие проверочными. Как показала практика, номера контрольных символов удобно выбирать по закону 2i, где i = 0, 1, 2 и т.д. – натуральный ряд чисел. Номера контрольных символов в этом случае будут соответственно: 1, 2, 4, 8, 16, 32 и т.д.
Затем определяют значения проверочных разрядов (0 или 1), руководствуясь следующим правилом: сумма единиц на проверочных позициях должна быть четной. Если эта сумма четна, то значение контрольного разряда – 0, в противном случае – 1.
Проверочные позиции выбираются следующим образом: составляется таблица для ряда натуральных чисел в двоичном коде. Число строк таблицы
n = k + r .
Первой строке соответствует проверочный символ a1 второй – a2 и т.д., как показано в таблице.
Таблица 5.11 – Ряд натуральных чисел в двоичном коде
Затем выявляют проверочные позиции, выписывая коэффициенты по следующему принципу:
в первую проверку входят коэффициенты, которые содержат в младшем разряде 1, т.е. a1, a3,, a5 , a7 , a9 ,a11 и т.д.;
во вторую – коэффициенты, содержащие 1 во втором разряде, т.е. и т.д. a2, a3,, a6 , a7 , a10 ,a11 и т.д.;
в третью проверку – коэффициенты, которые содержат 1 в третьем разряде, и т.д.
Номера проверочных коэффициентов соответствуют номерам проверочных позиций, что позволяет составить общую таблицу проверок.
Таблица 5.12 – Таблица проверок
Старшинство разрядов считается слева направо, а при проверке сверху вниз. Порядок проверок показывает также порядок следования разрядов в полученном двоичном коде.
Если в принятом коде есть ошибка, то результаты проверок по контрольным позициям образуют двоичное число, указывающее номер ошибочной позиции. Исправляют ошибку, изменяя символ ошибочной позиции на противоположный.
Для исправления одиночной и обнаружения двойной ошибки, кроме проверок по контрольным позициям, следует проводить еще одну проверку на четность для каждого кода. Чтобы осуществить такую проверку, следует к каждому коду в конце кодовой комбинации добавить контрольный символ таким образом, чтобы сумма единиц в полученной комбинации была всегда четной. Тогда в случае одной ошибки проверки по позициям укажут номер ошибочной позиции, а проверка на четность укажет наличие ошибки. Если проверки позиций укажут на наличие ошибки, а проверка на четность не фиксирует ошибки, значит в коде две ошибки.
Построить код Хэмминга для информационной комбинации 0101. Показать процесс обнаружения ошибки.
Количество информационных разрядов k = 4. Находим значения общей длины кодовой комбинации и число контрольных символов: r = 3 и n = 7. Так как общее количество символов кода n = 7, то контрольные коэффициенты займут три позиции: 1, 2 и 4.
Корректирующий код без значений контрольных коэффициентов будет иметь вид:
b1 b2 0 b3 1 0 1.
Пользуясь таблицей проверочных позиций, определяем значения контрольных коэффициентов.
Первая проверка: сумма П1 Å П3 Å П5 Å П7 должна быть четной, а сумма b1 Å 0 Å 1Å 1 будет четной при b1 = 0.
Вторая проверка: сумма П2 Å П3 Å П6 Å П7 должна быть четной, а сумма b2 Å 0 Å 0 Å 1 будет четной при b2 = 1.
Третья проверка: сумма П4 Å П5 Å П6 Å П7 должна быть четной, а сумма b3 Å 1Å 0 Å 1 будет четной при b3 = 0.
Окончательно корректирующий код принимает вид:
0 1 0 0 1 0 1.
Предположим, в результате искажений в канале связи вместо 0100101 было принято 0100111. Для обнаружения ошибки производим контроль на четность, аналогичные проверкам при выборе контрольных коэффициентов.
Первая проверка: сумма П1 Å П3 Å П5 Å П7 = 0 Å 0 Å 1Å 1 четна. В младший разряд номера ошибочной позиции записываем 0.
Вторая проверка: сумма П2 Å П3 Å П6 Å П7 = 1 Å 0 Å 1Å 1 нечетна. Во второй разряд номера ошибочной позиции записываем 1.
Третья проверка: сумма П4 Å П5 Å П6 Å П7 = 0 Å 1 Å 1Å 1 нечетна. В третий разряд номера ошибочной позиции записываем 1.
Номер ошибочной позиции 1102 = 610. Следовательно, символ шестой позиции следует изменить на обратный.
Самокорректирующиеся кодыПравить
Коды, в которых возможно автоматическое исправление ошибок, называются самокорректирующимися. Для построения самокорректирующегося кода, рассчитанного на исправление одиночных ошибок, одного контрольного разряда недостаточно. Как видно из дальнейшего, количество контрольных разрядов должно быть выбрано так, чтобы удовлетворялось неравенство или , где — количество информационных двоичных разрядов кодового слова. Минимальные значения k при заданных значениях m, найденные в соответствии с этим неравенством, приведены в таблице.
Наибольший интерес представляют двоичные блочные корректирующие коды. При использовании таких кодов информация передаётся в виде блоков одинаковой длины, и каждый блок кодируется и декодируется независимо от другого. Почти во всех блочных кодах символы можно разделить на информационные и проверочные или контрольные. Таким образом, все слова разделяются на разрешённые (для которых соотношение информационных и проверочных символов возможно) и запрещённые.
Основные характеристики самокорректирующихся кодов:
- Число разрешённых и запрещённых комбинаций. Если — число символов в блоке, — число проверочных символов в блоке, — число информационных символов, то — число возможных кодовых комбинаций, — число разрешённых кодовых комбинаций, — число запрещённых комбинаций.
- Избыточность кода. Величину называют избыточностью корректирующего кода.
- Минимальное кодовое расстояние. Минимальным кодовым расстоянием называется минимальное число искажённых символов, необходимое для перехода одной разрешённой комбинации в другую.
- Корректирующие возможности кодов.
Граница Плоткина даёт верхнюю границу кодового расстояния:
Граница Хэмминга устанавливает максимально возможное число разрешённых кодовых комбинаций:
где — число сочетаний из элементов по элементам. Отсюда можно получить выражение для оценки числа проверочных символов:
Для значений разница между границей Хэмминга и границей Плоткина невелика.
Граница Варшамова — Гилберта для больших n определяет нижнюю границу числа проверочных символов:
Все вышеперечисленные оценки дают представление о верхней границе при фиксированных и или оценку снизу числа проверочных символов.
Задание
ЗАДАНИЕ
1.
2.
3.
4.
Закодируйте слово 1101. Запишите решение в отдельном файле под пунктом 1.
Проверьте соответствует ли закодированное слово 1010111 исходному 1101.
Запишите решение с помощью матрицы в этом же файле под пунктом 2.
Закодируйте любое слово из 4 символов. Запишите решение в отдельном файле
под пунктом 3.
Умышленно сделайте одну ошибку. Передайте слово соседу для нахождения
ошибки.
Алгоритм декодированияПравить
Алгоритм декодирования по Хэммингу абсолютно идентичен алгоритму кодирования. Матрица преобразования соответствующей размерности умножается на матрицу-столбец кодового слова, и каждый элемент полученной матрицы-столбца берётся по модулю 2. Полученная матрица-столбец получила название «матрица синдромов». Легко проверить, что кодовое слово, сформированное в соответствии с алгоритмом, описанным в предыдущем разделе, всегда даёт нулевую матрицу синдромов.
Матрица синдромов становится ненулевой, если в результате ошибки (например, при передаче слова по линии связи с шумами) один из битов исходного слова изменил своё значение. Предположим для примера, что в кодовом слове, полученном в предыдущем разделе, шестой бит изменил своё значение с нуля на единицу (на рисунке обозначено красным цветом). Тогда получим следующую матрицу синдромов.
Заметим, что при однократной ошибке матрица синдромов всегда представляет собой двоичную запись (младший разряд в верхней строке) номера позиции, в которой произошла ошибка. В приведённом примере матрица синдромов (01100) соответствует двоичному числу 00110 или десятичному 6, откуда следует, что ошибка произошла в шестом бите.
Код с проверкой на четность
• Простейший корректирующий код – код с проверкой на четность,
который образуется добавлением к группе информационных
разрядов одного избыточного, значение которого выбирается таким
образом, чтобы сумма единиц в кодовой комбинации, т. е. вес
кодовой комбинации, была всегда четна.
• Пример. Рассмотрим код с проверкой на четность, образованный
добавлением контрольного разряда к простому коду из примера.
Информационные
Контрольный
разряды
разряд
0
000
0
1
001
1
2
010
1
3
011
0
4
100
1
5
101
0
6
110
0
• Необходимо вставить контрольные биты. Они
вставляются в строго определённых местах — это
позиции с номерами, равными степеням двойки.
• В нашем случае (при длине информационного
слова в 16 бит) это будут позиции 1, 2, 4, 8, 16.
Соответственно, получилось 5 контрольных бит
(выделены красным цветом):
• Таким образом, длина всего сообщения
увеличилась на 5 бит. До вычисления самих
контрольных бит им присваивается значение «0».
Простые коды
• Простые – коды, в которых используются все возможные 2n
комбинации, полученные при помощи n двоичных знаков.
• В таком коде всякая ошибка, состоящая в изменении 0 на 1
или 1 на 0, превращает одну информационную комбинацию в
другую. Для обнаружения и исправления ошибки в таком коде
необходима дополнительная информация.
• Пример. Пусть n=3. Тогда количество возможных кодовых
комбинаций 2n = 8. Простой код для n=3 будет иметь
следующий вид:
000
001
010
011
100
101
110
111
‘Вычисление третьего проверочного символа:
codeWord(4) = dataIn(1) Xor dataIn(2) Xor dataIn(3) Xor dataIn(7) Xor dataIn(8)
Xor dataIn(9) Xor dataIn(10)
‘Вычисление четвертого проверочного символа:
codeWord(8) = dataIn(4) Xor dataIn(5) Xor dataIn(6) Xor dataIn(7) Xor dataIn(8)
Xor dataIn(9) Xor dataIn(10)
‘Информационные символы:
codeWord(3) = dataIn(0)
codeWord(5) = dataIn(1)
codeWord(6) = dataIn(2)
codeWord(7) = dataIn(3)
codeWord(9) = dataIn(4)
codeWord(10) = dataIn(5)
codeWord(11) = dataIn(6)
codeWord(12) = dataIn(7)
codeWord(13) = dataIn(8)
codeWord(14) = dataIn(9)
codeWord(15) = dataIn(10)
Return codeWord
Код ХэммингаПравить
Построение кодов Хэмминга основано на принципе проверки на чётность числа единичных символов: к последовательности добавляется такой элемент, чтобы число единичных символов в получившейся последовательности было чётным:
Знак здесь означает сложение по модулю 2:
Если — то ошибки нет, если — то однократная ошибка.
Такой код называется или . Первое число — количество элементов последовательности, второе — количество информационных символов.
Для каждого числа проверочных символов существует классический код Хэмминга с маркировкой:
то есть — .
При иных значениях получается так называемый усечённый код, например международный телеграфный код МТК-2, у которого . Для него необходим код Хэмминга который является усечённым от классического
Для примера рассмотрим классический код Хемминга . Сгруппируем проверочные символы следующим образом:
Получение кодового слова выглядит следующим образом:
На вход декодера поступает кодовое слово
, где штрихом помечены символы, которые могут исказиться в результате действия помехи. В декодере в режиме исправления ошибок строится последовательность синдромов:
называется синдромом последовательности.
Получение синдрома выглядит следующим образом:
Кодовые слова кода Хэмминга приведены в таблице.
Синдром указывает на то, что в последовательности нет искажений. Каждому ненулевому синдрому соответствует определённая конфигурация ошибок, которая исправляется на этапе декодирования.
Для кода в таблице справа указаны ненулевые синдромы и соответствующие им конфигурации ошибок (для вида: ).
ПрименениеПравить
Код Хэмминга используется в некоторых прикладных программах в области хранения данных, особенно в RAID 2. Кроме того, метод Хэмминга давно применяется в памяти типа ECC и позволяет «на лету» исправлять однократные и обнаруживать двукратные ошибки.
Консольная программа, кодирующая код
Хэмминга (15, 11)
Логика алгоритма
• Допустим, есть сообщение из двух символов: «ha»,
которое необходимо передать без ошибок. Чтобы
сообщение закодировать при помощи Кода Хэмминга,
сначала необходимо представить его в бинарном виде.
• Надо определиться с длиной информационного слова, то
есть длиной строки из нулей и единиц, которая будет
кодироваться. Допустим, длина слова будет равна 16.
• Таким образом, любое исходное сообщение необходимо
разделить на блоки по 16 бит, которые будут потом
кодироваться отдельно друг от друга.
• Т.к. один символ занимает 8 бит, то в кодируемое слово
помещается два ASCII символа. В рассматриваемом
случае получили один бинарный блок 16 бит: «ha» .
Понятие о корректирующих кодах
• Обрабатываемая информация представляется
различными комбинациями из двух символов 0 и 1;
поэтому любой процесс кодирования состоит из
преобразования чисел и слов в соответствующие
последовательности символов 1 и 0.
Код – это совокупность всех комбинаций из
определенного количества символов (кодового
алфавита), которые избраны для представления
информации. Каждая такая комбинация называется
кодовой комбинацией.
• Общее число кодовых комбинаций в данном коде
может быть равно или меньше числа всех
возможных комбинаций из данного количества
символов.
• Принят код: 111100 исправлено 110100 – ошибка по
корректирующему числу в разряде 4;
111010 исправлено 101010 – ошибка по
корректирующему числу в разряде 5;
100000 исправлено 000000 – ошибка по
корректирующему числу в разряде 6
Цифра
0
1
2
3
4
5
6
7
Простой код
000
001
010
011
100
101
110
111
Код Хэмминга
6 5 4 3 2 1
0 0 0 0 0 0
0 0 0 1 1 1
0 1 1 0 0 1
0 1 1 1 1 0
1 0 1 0 1 0
1 0 1 1 0 1
1 1 0 0 1 1
1 1 0 1 0 0
Текущая версия страницы пока не проверялась опытными участниками и может значительно отличаться от версии, проверенной 2 марта 2021 года; проверки требуют 13 правок.
Код Хэ́мминга — самоконтролирующийся и самокорректирующийся код. Построен применительно к двоичной системе счисления.
Назван в честь американского математика Хэмминга Ричарда Уэсли, предложившего код.
Консольная программа, кодирующая и
декодирующая код (15, 11)
• Для проверки кодировщика и декодировщика
кода Хэмминга (15, 11), используя
вышеописанные функции, надо написать
консольную программу, можно использовать
любую среду разработки (Delphi, Visual Studio).
Вводится 11-разрядное число (от 0 до 0x7FF или
2047), и на выходе получаем 16-разрядное
число, представленное в виде двух байтов.
Корректирующие коды
• Основными характеристиками корректирующих кодов
являются их избыточность и корректирующая
способность.
Избыточность кода определяется по формуле k = n – m ,
где n – общее число знаков в коде;
m – число информационных знаков, необходимых для
изображения
N чисел или слов в простом коде, определяемое по
формуле
m = log2 N;
k – число контрольных знаков.
Например, для кода из примера: m = log2 4 = 2; k =1.
Часто для характеристики кода применяют понятие
относительная избыточность, которая определяется из
соотношения R = k / m.
Контрольные биты
КОНТРОЛЬНЫЕ БИТЫ
В исходное сообщение добавляется избыточность – контрольные биты
(обозначаются как ε), которые будут контролировать правильность
передачи каждого символа в сообщении.
Место расположение контрольных бит в исходном определяется по формуле :
№ -номер (положение)
№ε = 2i , где i = 0,1,2,3,4 и т.д. тогда № ε = 1,2,4,8,16,32,64,128,256 и т.д.
1
2
3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Формула кодового слова такова:
ε0 ε1 а1 ε2 а2 а3 а4 ε3 а5 а6 а7 а8 а9 а10 а11 ε4
Понятно, что количество ε в кодовой последовательности зависит от
количества символов в исходной.
Например: в последовательности из 4 символов их 3 (ε0 ε1 а1 ε2 а2 а3 а4 )
Корректирующие коды
• Корректирующие коды можно разделить на
систематические и несистематические.
• Систематические – такие n-значные коды,
которые содержат постоянное количество m
информационных и k = n m избыточных
знаков, причем эти знаки занимают одни и те же
позиции во всех кодовых комбинациях.
• Несистематические – такие коды, в которых
знаки закодированного числа или слова
разделить на информационные и контрольные
невозможно.
Консольная программа, декодирующая код
Хэмминга (15, 11)
При внесении битовой ошибки при декодировании, декодер
восстанавливает исходное закодированное число.
Алгоритм кодированияПравить
Предположим, что нужно сгенерировать код Хэмминга для некоторого информационного кодового слова. В качестве примера возьмём 15-битовое кодовое слово хотя алгоритм пригоден для кодовых слов любой длины. В приведённой ниже таблице в первой строке даны номера позиций в кодовом слове, во второй — условное обозначение битов, в третьей — значения битов.
Добавим к таблице 5 строк (по количеству контрольных битов), в которые поместим матрицу преобразования. Каждая строка будет соответствовать одному контрольному биту (нулевой контрольный бит — верхняя строка, четвёртый — нижняя), каждый столбец — одному биту кодируемого слова. В каждом столбце матрицы преобразования поместим двоичный номер этого столбца, причём порядок следования битов будет обратный — младший бит расположим в верхней строке, старший — в нижней. Например, в третьем столбце матрицы будут стоять числа 11000, что соответствует двоичной записи числа три: 00011.
В правой части таблицы оставили пустым один столбец, в который поместим результаты вычислений контрольных битов. Вычисление контрольных битов производим следующим образом: берём одну из строк матрицы преобразования (например, ) и находим её скалярное произведение с кодовым словом, то есть перемножаем соответствующие биты обеих строк и находим сумму произведений. Если сумма получилась больше единицы, находим остаток от его деления на 2. Иными словами, мы подсчитываем, сколько раз в кодовом слове и соответствующей строке матрицы в одинаковых позициях стоят единицы, и берём это число по модулю 2.
Например, для строки :
= (1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·1+0·1+1·1+0·0+1·0+0·0+1·0+0·1) mod 2 = 5 mod 2 = 1.
Полученные контрольные биты вставляем в кодовое слово вместо стоявших там ранее нулей. По аналогии находим проверочные биты в остальных строках. Кодирование по Хэммингу завершено. Полученное кодовое слово — 11110010001011110001.
• Как же вычислить значение каждого
контрольного бита?
• Делается это просто: берут каждый контрольный
бит и смотрят, сколько среди контролируемых
им битов единиц, получают некоторое целое
число и, если оно чётное, то ставят ноль, в
противном случае ставят единицу.
Матрица Хэмминга
МАТРИЦА ХЭММИНГА
Используется для построения кодовой последовательности (определения
значений контрольных бит), а также для проверки на стороне получателя
используется проверочная матрица Хэмминга.
Выбор размера матрицы зависит от количества символов в исходном
сообщении.
Например, если у нас исходная последовательность из 4 символов, то ε будет в
количестве 3 и матрица будет (7х3) :
3– высоту матрицы определяет количество ε. (ε0, ε1, ε2 см. слайд 3),
7- количество символов с добавленными ε
Н=
0 0 0 1 1 1 1 h0
0 1 1 0 0 1 1 h1
1 0 1 0 1 0 1 h2
ε0 ε1 а1 ε2 а2 а3 а4
1 – 001
2 – 010
3 – 011
4 – 100
5 – 101
6 – 110
7 – 111
Вычисление контрольных бит.
• Значение каждого контрольного бита зависит от
значений информационных бит, но не от всех, а
только от тех, которые этот контрольных бит
контролирует.
• Для того, чтобы понять, за какие биты отвечает
каждых контрольный бит, необходимо понять
простую закономерность: контрольный бит с
номером N контролирует все последующие N
бит через каждые N бит, начиная с позиции N.
• Требуется написать кодировщик, который будет
получать на вход 11 бит данных, кодировать их и
возвращать 15 бит выходной информации.
Т.е. параметр кода Хэмминга (15, 11).
Возвращает кодер 16 бит (кодовое слово):
• кодовое слово дополняется одним битом слева,
чтобы длина была равна степени двойки. Сейчас
этот бит никак не используется. Можно его
использовать как бит чётности и получить так
называемый дополненный код Хэмминга.
‘Результат декодирования с учетом коррекции (11 бит выходных данных):
Dim outData As New BitArray(11)
outData(0) = codeWord(3) Xor correction(0)
outData(1) = codeWord(5) Xor correction(1)
outData(2) = codeWord(6) Xor correction(2)
outData(3) = codeWord(7) Xor correction(3)
outData(4) = codeWord(9) Xor correction(4)
outData(5) = codeWord(10) Xor correction(5)
outData(6) = codeWord(11) Xor correction(6)
outData(7) = codeWord(12) Xor correction(7)
outData(8) = codeWord(13) Xor correction(8)
outData(9) = codeWord(14) Xor correction(9)
outData(10) = codeWord(15) Xor correction(10)
Dim masks(31) As Integer
masks(0) = BitVector32.CreateMask()
For i As Integer = 1 To 31
masks(i) = BitVector32.CreateMask(masks(i – 1))
Next
Dim v As New BitVector32
For i As Integer = 0 To 10
v(masks(i)) = outData(i)
Next
Dim decoded As Integer = v.Data
Return decoded
Коды равномерные и неравномерные
• Равномерные – коды, в которых все комбинации
имеют одинаковое количество знаков.
• Неравномерные –коды, в которых количество
знаков может быть различным. Примером такого
кода может служить телеграфный код Морзе.
• При помощи n двоичных знаков, очевидно,
можно получить 2n кодовых комбинаций. В
зависимости от того, все возможные 2n кодовые
комбинации задействованы для представления
информации или нет, коды подразделяются на
простые и корректирующие (избыточные).
Корректирующие коды
• Корректирующая способность кода количественно
может быть определена вероятностью обнаружения или
исправления ошибок различных типов. Разработка кодов,
имеющих максимальную корректирующую способность
при заданной избыточности, а также кодов,
обеспечивающих заданную корректирующую способность
при минимальной избыточности, – одна из важнейших
задач теории кодирования.
• Корректирующая способность кода связана с понятием
кодового расстояния. Прежде чем сформулировать
определение кодового расстояния, введем понятие о весе
кодовой комбинации.
• Вес, W(A), кодовой комбинации A определяется
количеством содержащихся в ней двоичных единиц.
• Пример:
для А = 111001, W (A) = ai = 4.
Код Хэмминга. Пример работы
алгоритма
К существующим k контрольным разрядам может еще
добавляться (k+1)-й разряд, обеспечивающий
дополнительный контроль по четности всей кодовой
комбинации.
При проверке информации после ее приема возможны три
случая:
• отсутствие ошибок – корректирующее число равно 0, общая
четность суммы единиц кодовой комбинации правильна;
• одиночная ошибка – контроль общей четности кодовой
комбинации обнаруживает ошибку, корректирующее число
указывает номер искаженного разряда (если
корректирующее число равно нулю, то ошибка произошла в
разряде общей четности);
• двойная ошибка – корректирующее число не равно нулю,
контроль общей четности кодовой комбинации не
обнаруживает ошибки.
Корректирующие коды
• Минимальное кодовое расстояние кода – это
минимальное расстояние между двумя любыми
комбинациями в этом коде.
• Если, например, в коде есть хотя бы одна пара
комбинаций, которые отличаются друг от друга
только в одной позиции, то минимальное
расстояние этого кода = 1. Так, для простого
кода из первого примера = 1, а для
корректирующего кода из второго примера
= 2.
Рассмотрим некоторые корректирующие коды.
Транспортированное кодовое слово
ТРАНСПОРТИРОВАННОЕ
КОДОВОЕ СЛОВО
1) Построение кодового слова: рассмотрим на примере
Пусть дано информационное слово а = (1 0 0 1) – его надо зашифровать
1234
a1=1, a2=0, a3=0, a4=1
То предварительно кодовое слово будет выглядеть:
ε0 ε1 1 ε2 0 0 1
Далее определяем значение контрольных бит по формулам:
ε0 = а1 ⨁ а2 ⨁ а4 = 1 ⨁ 0 ⨁ 1 = 0
⨁ – XOR
ε1 = а1 ⨁ а3 ⨁ а4 = 1 ⨁ 0 ⨁ 1 = 0
1 ⨁ 1=0
0 ⨁ 0=0
ε2 = а2 ⨁ а3 ⨁ а4 = 0 ⨁ 0 ⨁ 1 = 1
1 ⨁ 0=1
1 ⨁ 0=1
Составляем кодовое слово, оно будет называться транспонированное
кодовое слово:
Rt= 0 0 1 1 0 0 1 которое будем передавать
Код с проверкой на четность
• Таким образом, если в простом коде число 4 имеет
изображение 100, то в коде с проверкой на четность оно
будет изображаться комбинацией 1001.
• Минимальное кодовое расстояние кода с проверкой на
четность = 2. Такой код обнаруживает все одиночные
ошибки и групповые ошибки нечетной кратности, так как
четность количества единиц в этом случае будет также
нарушаться.
• Следует отметить, что при кодировании целесообразно
число единиц в кодовой комбинации делать нечетным и
проводить контроль на нечетность, в этом случае любая
комбинация, в том числе и изображающая нуль, будет
иметь хотя бы одну единицу, что дает возможность отличить
полное отсутствие информации от передачи нуля.
• Рассмотрим самый простой алгоритм Хемминга,
который может исправлять лишь одну ошибку.
• Существуют модификации данного алгоритма,
позволяющие обнаруживать (и если возможно
исправлять) большее количество ошибок.
• Код Хэмминга состоит из двух частей.
• Первая часть кодирует исходное сообщение, вставляя
в него в определённых местах контрольные биты
(вычисленные особым образом).
• Вторая часть получает входящее сообщение и заново
вычисляет контрольные биты (по тому же алгоритму,
что и первая часть). Если все вновь вычисленные
контрольные биты совпадают с полученными, то
сообщение получено без ошибок. Иначе делается
вывод о наличии ошибки и при возможности ошибка
Декодирование и исправление ошибок.
• Теперь, допустим, закодированное сообщение пришло с
ошибкой. Пусть 11-ый бит передался неправильно:
• Алгоритм декодирования заключается в том, что
необходимо заново вычислить все контрольные биты (так
же как при кодировании) и сравнить их с контрольными
битами, которые были получены. Посчитав контрольные
биты с неправильным 11-ым битом, получаем :
• Контрольные биты под номерами: 1, 2, 8 не совпадают с
такими же контрольными битами, которые были
получены. Теперь, сложив номера позиций неправильных
контрольных бит (1 + 2 + 8 = 11), получаем позицию
ошибочного бита. Инвертировав его и отбросив
контрольные биты, получаем исходное сообщение в
первозданном виде!
• Код Хэмминга – это алгоритм, который позволяет
закодировать какое-либо информационное
сообщение определённым образом и после
передачи (например по сети) определить
появилась ли какая-то ошибка в этом сообщении
(к примеру из-за помех) и, при возможности,
восстановить это сообщение.
• Таким образом, код Хэмминга самоконтролирующийся и
самокорректирующийся код. Построен он
применительно к двоичной системе счисления.
Dim codeWord As New BitArray(b) ’16 бит входных данных
‘ Процесс декодирования – это сложение по модулю 2 бит
информационного слова, по весу полученных единиц в результате –
получение позиции ошибки.
Dim syndrome As New BitArray(4)
‘Вычисление первого проверочного символа из полученного кодового
слова и далее сравнение его с полученным.
syndrome(0) = codeWord(3) Xor codeWord(5) Xor codeWord(7)
Xor codeWord(9) Xor codeWord(11) Xor codeWord(13) Xor
codeWord(15) Xor codeWord(1)
‘Вычисление второго проверочного символа из полученного кодового
слова и далее сравнение его с полученным.
syndrome(1) = codeWord(3) Xor codeWord(6) Xor codeWord(7)
Xor codeWord(10) Xor codeWord(11) Xor codeWord(14) Xor
codeWord(15) Xor codeWord(2)
‘Вычисление третьего проверочного символа из полученного кодового
слова и далее сравнение его с полученным.
syndrome(2) = codeWord(5) Xor codeWord(6) Xor codeWord(7)
Xor codeWord(12) Xor codeWord(13) Xor codeWord(14) Xor
codeWord(15) Xor codeWord(4)
• Здесь знаком «X» обозначены те биты, которые
контролирует контрольный бит, номер которого
справа.
• То есть, к примеру, бит номер 12 контролируется
битами с номерами 4 и 8.
• Чтобы узнать какими битами контролируется бит
с номером N надо разложить N по степеням
двойки.
Параметры кода Хэмминга
• Параметры кода указываются так: (7, 4). Это означает, что
длина кодового слова равна 7 битам, а длина сообщения
– 4 бита.
• В зависимости от количества информационных и
проверочных разрядов в кодовых словах существуют коды
Хэмминга (7,4), (9,5), (11, 7), (15, 11), (31, 26), (63, 57) и т. д.
• Общий вид формулы, по которой определяются виды
кодов Хэмминга по соотношению числа информационных
символов к проверочным: (2x − 1, 2x − x − 1), где x –
натуральное число.
• При декодировании есть вероятность, что исходное
сообщение нельзя будет восстановить, в случае
превышения числом ошибок корректирующей
способности кода.
• Однако помехоустойчивость закодированной
информации всё равно выше, чем у незакодированной.
ИсторияПравить
В середине 1940-х годов в лаборатории Белла была создана счётная машина Bell Model V. Это была электромеханическая машина, использующая релейные блоки, скорость которых была очень низка: одна операция за несколько секунд. Данные вводились в машину с помощью перфокарт с ненадёжными устройствами чтения, поэтому в процессе чтения часто происходили ошибки. В рабочие дни использовались специальные коды, чтобы обнаруживать и исправлять найденные ошибки, при этом оператор узнавал об ошибке по свечению лампочек, исправлял и снова запускал машину. В выходные дни, когда не было операторов, при возникновении ошибки машина автоматически выходила из программы и запускала другую.
Хэмминг часто работал в выходные дни и всё больше раздражался, так как должен был перезагружать свою программу из-за ненадёжности считывателя перфокарт. На протяжении нескольких лет он искал эффективный алгоритм исправления ошибок. В 1950 году он опубликовал способ кодирования, который известен как код Хэмминга.
История и НАЗНАЧЕНИЕ
ИСТОРИЯ И НАЗНАЧЕНИЕ
В середине 1940-х годов Ричард Хэмминг работал в знаменитых Лабораториях Белла
на счётной машине Bell Model V. Это была электромеханическая машина,
использующая релейные блоки, скорость которых была очень низка: один оборот
за несколько секунд. Данные вводились в машину с помощью перфокарт, и
поэтому в процессе чтения часто происходили ошибки. В рабочие дни
использовались специальные коды, чтобы обнаруживать и исправлять найденные
ошибки, при этом оператор узнавал об ошибке по свечению лампочек, исправлял и
запускал машину. В выходные дни, когда не было операторов, при возникновении
ошибки машина автоматически выходила из программы и запускала другую.
Хэмминг часто работал в выходные дни, и все больше и больше раздражался, потому
что часто был должен перезагружать свою программу из-за ненадежности
перфокарт. На протяжении нескольких лет он проводил много времени над
построением эффективных алгоритмов исправления ошибок. В 1950 году он
опубликовал способ, который на сегодняшний день известен как код Хэмминга.
Код Хэмминга используется для обнаружения и исправления ошибок в двоичных
сообщениях (в прикладных программах в области хранения данных, особенно в
RAID 2);
Корректирующие коды
• Кодовое расстояние между двумя кодовыми
комбинациями определяется числом позиций, в которых
их элементы не совпадают.
• Это означает, что кодовое расстояние между
комбинациями А и В равно весу некоторой третьей
комбинации С, полученной поразрядным сложением
двух этих комбинаций в соответствии со следующей
формулой:
W(C) = W(A B) = ( ai bi).
• Пример.Пусть есть кодовая комбинация А = 111001 и
кодовая комбинация В = 100101, тогда
111001
100101
________
C = 011100 W(C) = 3, кодовое расстояние между А и В.
Систематические кодыПравить
Систематические коды образуют большую группу из блочных, разделимых кодов (в которых все символы слова можно разделить на проверочные и информационные). Особенностью систематических кодов является то, что проверочные символы образуются в результате линейных логических операций над информационными символами. Кроме того, любая разрешенная кодовая комбинация может быть получена в результате линейных операций над набором линейно независимых кодовых комбинаций.
Самоконтролирующиеся кодыПравить
Коды Хэмминга являются самоконтролирующимися кодами, то есть кодами, позволяющими автоматически обнаруживать ошибки при передаче данных. Для их построения достаточно приписать к каждому слову один добавочный (контрольный) двоичный разряд и выбрать цифру этого разряда так, чтобы общее количество единиц в изображении любого числа было, например, нечётным. Одиночная ошибка в каком-либо разряде передаваемого слова (в том числе, может быть, и в контрольном разряде) изменит чётность общего количества единиц. Счётчики по модулю 2, подсчитывающие количество единиц, которые содержатся среди двоичных цифр числа, дают сигнал о наличии ошибок. При этом невозможно узнать, в какой именно позиции слова произошла ошибка, и, следовательно, нет возможности исправить её. Остаются незамеченными также ошибки, возникающие одновременно в двух, четырёх, и т. д. — в чётном количестве разрядов. Предполагается, что двойные, а тем более многократные ошибки маловероятны.
Корректирующие коды
• Корректирующие – коды, в которых лишь некоторая часть
всех возможных 2n комбинаций, полученных при помощи
n двоичных знаков, используется для представления
информации.
• В таком коде все остальные кодовые комбинации
являются запрещенными, и их появление свидетельствует
о наличии ошибки. Любая одиночная ошибка в таком
коде превращает информационную комбинацию в
запрещенную.
• Пример. Пусть n=3, но из всех возможных кодовых
комбинаций, представленных в предыдущем примере,
только четыре изображают числа от 0 до 3, а остальные
считаются запрещенными. Такой корректирующий код
будет иметь следующий вид:
000
011
101
Код Хэмминга
• Код Хэмминга строится таким образом, что к
имеющимся информационным разрядам кодовой
комбинации добавляется вычисленное по
вышеприведенной формуле количество контрольных
разрядов, которые формируются путем подсчета
четности суммы единиц для определенных групп
информационных разрядов.
• При приеме такой кодовой комбинации из полученных
информационных и контрольных разрядов путем
аналогичных подсчетов четности составляют
корректирующее число, которое равно нулю, при
отсутствии ошибки, либо указывает номер ошибочного
разряда.
ЛитератураПравить
- Питерсон У., Уэлдон Э. Коды, исправляющие ошибки: Пер. с англ. М.: Мир, 1976, 594 c.
- Пенин П. Е., Филиппов М.Р. Радиотехнические системы передачи информации. М.: Радио и Связь, 1984, 256 с.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. Пер. с англ. М.: Мир, 1986, 576 с.