

Коды с обнаружением и исправлением ошибок. Код хемминга
Код
Хемминга относится к блоковым кодам.
Наиболее простой код, исправляющий
ошибки кратности t=1,
имеет кодовое расстояние d=3.
1)
На передающей стороне к k
информационным символам добавляется
r
проверочных
символов. Значения проверочных символов
(0 или 1) определяются путем проверок на
четность. В проверку на четность включают
определенные элементы кодовых комбинаций,
образующие проверочную группу.
Сформированный n-разрядный
код, состоящий из k
информационных и r
проверочных элементов, передается в
линию связи.
2)
На приемной стороне в тех же проверочных
группах производится r
проверок на четность.
3)
Проверочные группы строятся таким
образом, чтобы записи результатов каждой
проверки

в двоичной форме давало бы r-разрядное
двоичное число

Для
того чтобы
обнаружить и исправить все ошибки
кратности 1, число проверочных символов
выбирается из соотношения

Число
элементов помехоустойчивой кодовой
комбинации определяется из решения
уравнения относительно n:

.
(4.6)
Изначально
известно число k.
Определив n
из уравнения (4.6), получим число проверочных
разрядов r
в новых
кодовых комбинациях (таблица 4.1).
Таблица
4.1 – Соотношение числа информационных
и проверочных разрядов
Выбор значений
и позиций проверочных элементов
При
наличии ошибки двоичный код синдрома
ошибки должен указать номер разряда
кодовой комбинации (в исчислении с
основанием 10), в котором произошло
искажение элемента.
Единица
в первом разряде синдрома ошибки
появляется при искажении любого нечетного
разряда кодовой комбинации.
То
есть в первую проверку должны входить
все элементы кодовой комбинации, в
первом (младшем) разряде содержится 1.
Если

,
то один из элементов искажен.
Аналогично,
во вторую проверочную группу должны
входить все элементы кодовой комбинации,
во втором разряде которых содержится
1.
Если
S2=1,
то один из элементов искажен:
Третья
проверочная группа содержит элементы,
принимающие значение 1 в третьем разряде
новой кодовой комбинации:
Четвертая
проверочная группа содержит элементы,
принимающие значение 1 в четвертом
разряде новой кодовой комбинации:
Обозначим
проверочные символы как

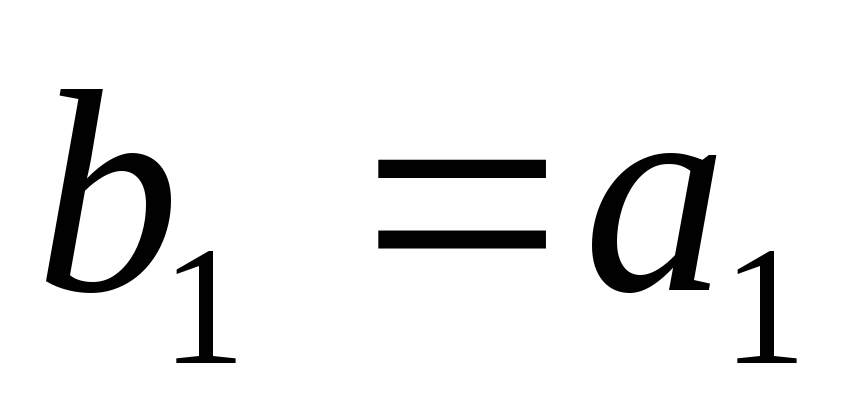



.
(4.11)
1
0 0 0 0 1 1 – исходная кодовая комбинация
(младший разряд слева), k=7.
По
таблице 4.1 найдем число проверочных
символов
r=4.
Помехоустойчивая кодовая комбинация
должна содержать n=k+r
=11 элементов
(разрядов)
k1
k2
k3
k4
k5
k6
k7
а1
а2
а3
а4
а5
а6
а7
а8
а9
а10
а11
(а1
– младший разряд).
b1
b2
b3
b4
Выполнив
проверку на четность по описанным выше
правилам, определим значения проверочных
элементов:
Получится
новая кодовая комбинация 01100000011,
содержащая информационные биты и
проверочные биты.
Пусть
принят код 01101000011, то есть произошла
ошибка в 5-м разряде.
Проверочные группы
на приемной стороне:
Таким образом,
синдром ошибки

,
то есть, выявлена ошибка в бите

Для
ее исправления надо выполнить операцию
суммирования а5
с 1 по модулю 2: а5=
а51.
зона, окружающая каждую разрешенную кодовую комбинацию.
При декодировании кодовые комбинации, попадающие в эту зону, отождествляются с разрешенной. Трехкратная ошибка в В1р(отмечено стрелкой) переводит эту, комбинацию в зону В2р и при декодировании будет решено, что передавалась В, (ошибки не исправлены).
Пример 18.1. Кодовое расстояние корректирующего кода dо=4. Ошибки
какой кратности данный код может обнаруживать или исправлять?
Из (18.3) и (18.4) следует, что qo.ош <do — 1 и qи.ош ≤(do -1)/2. При do=4
получаем: кратность обнаруживаемых ошибок qo.ош≤ 3; кратность исправляемых
ошибок qи.ош =1.
Пример 18.2. Чему должно быть равно кодовое расстояние do, достаточное для исправления трехкратных ошибок?
Подставляя в (18.4) значение qи.ош =3, получаем do≥7.
Итак, задача получения кода с заданной корректирующей способностью сводится к задаче формирования в кодере М, разрешенных кодовых комбинаций с требуемым минимальным расстоянием do. Исследования показывают, что хороший корректирующий
разрешенными. Это наглядно показывает приведенный ниже пример.
Пример 18.3. Определить время декодирования сравнением принятой кодовой комбинации со всеми разрешенными при k=48, если для этого используется ЭВМ, производящая 107 оп./с.
Будем считать, что для сравнения принятой кодовой комбинации с одной
из разрешенных достаточно одной операции на ЭВМ. Всего необходимо провести Мa— 1
248 сравнений, и на это потребуется время Т=248/7=2,8*107 с
325,8 суток, т. е. около 11 месяцев.
Как видно из примера 18.3, задача декодирования простым перебором и сравнением непосильна даже для современных ЭВМ (и, пожалуй, ЭВМ будущего). На практике получили распространение такие методы кодирования и декодирования, которые не требуют перебора при декодировании и имеют приемлемую сложность реализации.
Всякому ненулевому синдрому соответствует определенное расположение ошибок.
Достаточно ли знание синдрома для исправления ошибки? В общем случае — нет. Требуется еще знать, на какой символ необходимо заменять ошибочный. Но для двоичных кодов исправление ошибки производится единственным образом — инверсией
символов (0 заменяется на 1 и 1 на 0), поэтому знание синдрома является необходимым и достаточным условием для исправления ошибок в двоичных кодах.
Таким образом, синдромное декодирование двоичных кодон сводится к вычислению тем или другим способом синдрома, по которому обнаруживаются и исправляются ошибки. Десятки предложенных до настоящего времени корректирующих кодов как раз и отличаются способами формирования проверочных символов и вычисления синдрома при декодировании.
Классификация корректирующих кодов. Исходя из основных параметров и способов кодирования и декодирования, корректирующие коды в первую очередь можно разделить нг блочные и непрерывные. Блочные коды характеризуются тем, чтo каждому знаку алфавита соответствует блок (кодовая комбинация) из и элементов. Операции кодирования и декодирования r каждом блоке производятся отдельно. Особенностью непрерывных кодов является то, что информационная последовательность не разделяется на блоки, а проверочные символы размещаются по определенному правилу между информационными. Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно указать информационные и проверочные символы. Н
неразделимых кодах такое разделение символов провести невозможно.
Разделимые коды, в свою очередь, делятся на систематические и несистематические. Систематическими называются коды, у которых сумм а по модулю два двух разрешенных кодовых комбинаций дает снова разрешенную кодовую комбинацию. Кроме того, и систематическом коде информационные символы, как правило, не изменяются при кодировании и занимают определенные заранее заданные места. Проверочные символы вычисляются как линейная комбинация информационных. Отсюда возникает и другое название систематических кодов — линейные. Для систематических кодов применяется обозначение (и, k)-код, где n — общее число символов в кодовой комбинации, k — число информационных символов. В несистематических кодах приведенные выше правила не выполняются.
18.3. К ОДЫ С ПОСТОЯННЫМ ВЕСОМ
Из названия кода следует, что все разрешенные кодовые комбинации такого кода имеют одинаковое число единиц. Напомним (см. §18.1), что весом называется число единиц в кодовой комбинации. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь нельзя выделить информационные и проверочные символы.
Типичным примером кода с постоянным весом является семиэлементный телеграфный код # 3 (МТК-З), рекомендованный Международным консультативным комитетом по телефонии и телеграфии (МККТТ) для использования в системах с обратной связью с целью обнаружения ошибок. Вес кода равен трем, следовательно, каждая разрешенная кодовая комбинация имеет три единицы и четыре нуля. В МТК-3 из общего числа кодовых комбинаций Мo=27=128 разрешенными являются лишь Мa=СЗ7=35 поэтому в соответствии с (18.1) относительная скорость кода Rk== log235/ log2128=0,73. Декодирование принятых кодовых комбинаций в коде с постоянным весом сводится к вычислению их веса (подсчета числа единиц). Если вес отличается от заданного, то выносится решение, что комбинация принята с ошибкой. Например, легко определить, что из трех принятых кодовых комбинаций МТК-3; 1011000, 110101, 010101, — ошибки имеются во второй, поскольку ее вес равен четырем. Этот код обнаруживает все ошибки нечетной кратности и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Характерным для ошибок смещения является то, что число
искаженных единиц всегда равно числу искаженных нулей, поэтому коды с постоянным весом наиболее эффективны в каналах, где вероятность ошибок смещения невелика.
18.4. К ОД С ЧЕТНЫМ ЧИСЛОМ ЕДИНИЦ
Это систематический (k+ 1, k)-код, в котором операции кодирования и декодирования проводятся как проверка на четность. Кодовое расстояние для этого кода dо = 2. При этом согласно (18.3) код всегда обнаруживает однократные ошибки. Разрешенная комбинация этого кода при любом числе информационных символов имеет всего один проверочный. Размещение проверочного символа в кодовой комбинации не имеет значения. Обычно его ставят в конце после информационных. Значение символа в проверочном разряде выбирается из условия, что общее число единиц в образованной таким образом разрешенной кодовой комбинации было четным (отсюда и название кода), т. е. чтобы сумма по модулю для всех символов кодовой комбинации равнялась нулю.
где, как и раньше, знак
Пример 18.4. Необходимо передать кодом с четным числом единиц кодовую комбинацию 10110. Проверочный символ в соответствии с выражением (18.5), bk+1=1
0=1. Следовательно, передаваемая кодовая комбинация будет иметь вид
информационные символы проверочный символ
Пусть будет принята комбинация 101001. Контрольная сумма C1=1
1=1≠0, что свидетельствует о наличии ошибки. Нарушение четности имеет место при появлении не только однократных, но и любых ошибок нечетной кратности, что дает возможность их обнаружить. Появление четных ошибок не изменяет четности контрольной суммы (18.6), поэтому такие ошибки кодом с четным числом единиц не обнаруживаются.
К достоинствам рассмотренного кода следует отнести простоту кодирующих и декодирующих устройств, малую избыточность xи=1/(1+k). Однако этот код имеет сравнительно низкую корректирующую способность, ограничивающую его применение.
18.5. Ц ИКЛИЧЕСКИЕ КОДЫ
Циклические коды относятся к систематическим кодам. Они получили название благодаря своему свойству: циклическая перестановка символов разрешенной кодовой комбинации дает снова разрешенную кодовую комбинацию. При циклической перестановке
символы кодовой комбинации перемещаются слева направо на одну позицию, причем крайний правый символ переносится на место
крайнего левого. Например, с А1 =101 100 циклической перестановкой получаем А2=010110.
Запись полинома обычно упрощают, опуская сомножители аi=1 и вычеркивая слагаемые, в которые входит аj=О. Например, кодовая комбинация А1=101100 представляется полиномом А1(х) =х5+х3+х2, а A2 = 010110 — полиномом А2(х) =х4+х2+х.
Операции над многочленами. При формировании кодовых комбинаций циклического кода и вычислении синдрома используются такие операции, как сложение, вычитание, умножение и деление многочленов. Они выполняются по обычным арифметическим правилам, только суммирование производится как сложение по модулю два, а вычитание заменяется суммированием. Покажем выполнение этих операций на конкретных примерах ранее приведенных полиномов A1(x) и А2(х):
А1(х)+А2(х) =А1(х) — А2(х) =х5+х3+х2+х4+х1+х=
=х5+х4+х3+х поскольку х2+х2=х2(1
А1(х) А2(х) = (х5+х3+х2) (х4+х2+х) =х9+х7
+х6+х7+х5+х4+х6+х4+хз = х9+х5+х3.
x5 +х3+ х2
Формирование разрешенных кодовых комбинаций. Разрешенные кодовые комбинации цикличесокго кода обладают важным отличительным признаком: все они без остатка
делятся на полином G(x), называемый образующим, или порождающим. Из этого свойства следует весьма простой способ формирования разрешенных кодовых комбинаций — умножение комбинаций первичного кода Аi(х) на порождающий полипом G(x):
Вip(х) =Аi(х)G(х). (18.7)
В теории циклических кодов доказывается, что порождающими
могут быть только полиномы, которые являются делителями двучлена хn + l. Такие полиномы, найденные с помощью ЭВМ, сведены в обширные таблицы. Некоторые из них приведены в табл. 18.1. Следует отметить, что с увеличением максимальной степени
порождающих полиномов r резко увеличивается их количество.
Так, при r=3 имеется всего два полинома, при r=10 их уже несколько десятков.
Для формирования разрешенных кодовых комбинаций по алгоритму (18.7) может быть использован любой порождающий полином, лишь бы его максимальная степень была равна числу необходимых проверочных символов. Однако в полученной таким способом комбинации В~~(х) в явном виде не содержатся информационные символы (получаем неразделимый код), поэтому на практике используют другой способ кодирования, позволяющий представить кодовую комбинацию Вiр в виде разделенных информационных и проверочных символов:
Bip(x) =Аi(х)хr +R(x),
где R(x) — остаток от деления Аi(х)хr/G(х).
В алгоритме (18.8) можно выделить три этапа формирования
разрешенных кодовых комбинаций:
1) к комбинации первичного
кода Аi дописывается справа r нулей, что эквивалентно умножению Аi(х) на хr;
2) произведение Аi(х)х’ делится на порождающий полином G(х) и определяется остаток R(х), степень которого не превышает r — 1;
3) вычисленный остаток присоединяется к
Аi (х) хr.
Таблица 18.1. Порождающие полиномы 6(х) циклических кодов
Пример 18.5. Для кодовой комбинации Аi =1011 сформировать кодовую
комбинацию циклического кода (7, 4).
В заданном цикличеоком коде n=7, k=4, r=3 и из табл. 18.1 выберем
порождающий полином G(х)=х3+х2+1. Проделаем необходимые операции по
получению кодовой комбинации циклического кода согласно алгоритму (18.8):
Полученная кодовая комбинация циклического кода может быть также записана в виде Bip =1011100, где первые четыре символа являются информационными, последние три — проверочными.
Синдром циклического кода. Для определения синдрома циклического кода достаточно поделить принятую кодовую комбинацию на порождающий полином. Остаток от деления и является синдромом. Если принятая комбинация — разрешенная, то остаток от деления будет нулевым. Ненулевой остаток свидетельствует о наличии в принятой комбинации ошибок.
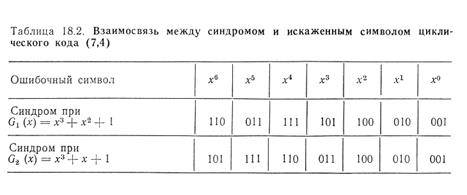
Взаимосвязь между синдромом (остатком) и ошибочным символом находится достаточно просто. Необходимо взять любую разрешенную кодовую комбинацию, ввести ошибку в определенный символ и выполнить деление на G(х). Полученный остаток
(синдром) и будет указывать на ошибку в этом символе. Для циклического кода (7,4) взаимосвязь между синдромом и ошибочным символом при различных порождающих полиномах приведена в табл. 18.2. Пользуясь этой таблицей, по синдрому можно найти
местоположение ошибки и исправить ее.
Пример 18.6. Принятая кодовая комбинация циклического кода (7,4) имеет
вид В’ip= 1010101. Определить и исправить ошибку в В’ip если она имеется.
Порождающий полипом кода G(х) =х3+х+1.
Проводим операцию деления В’iр(х)/G(«):
По табл. 18.2 находим, что синдрому (С(х) =х2+x=110 соответствует ошибочный символ х4. Инвертировав его, получим принятую кодовую комбинацию без ошибки Вip=1000101.
Применение циклических кодов. Циклические коды просты в реализации. Все приведенные выше операции умножения, сложения и деления полиномов осуществляются на регистрах сдвига. Кроме того, эти коды обладают высокой корректирующей способностью. Можно сформировать циклический код с любым, наперед заданным значением кодового расстояния do. Поэтому они рекомендованы МККТТ для применения в аппаратуре передачи данных. Так, согласно Рекомендации V.41, в системах передачи данных с обратной связью следует применять код с по рождающим полиномом G(x) =х16+х12+х5+1. Можно сказать, что
в современной аппаратуре с коррекцией ошибок применяются, в
основном, циклические коды.
Связь корректирующей способности кода с кодовым расстоянием
Из предыдущего следует, что при взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием. Оно выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d.
Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих комбинаций по модулю 2. Например:
Минимальное расстояние, взятое по всем парам разрешенных комбинаций кода, называют минимальным кодовым расстоянием.
Декодирование после приема может производиться таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии.
Такое декодирование называется декодированием по методу максимального правдоподобия.
Очевидно, что при d = 1 все кодовые комбинации являются разрешенными. Например, при n = 3 разрешенные комбинации образуют следующее множество: 000, 001, 010, 011, 100, 101, 110, 111.
Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью.
Если d = 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в них числа единиц, как это приведено ниже для n = 3:
Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности. В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т.е. d ≥ r + 1.
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую.
Для исправления одиночной ошибки каждой разрешенной кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций. Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При n = 3 за разрешенные комбинации можно, например, принять 000 или 111. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате возникновения единичной ошибки в комбинации 000.
Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
В общем случае для исправления ошибок кратности S d между РКК должно удовлетворять соотношению:
d ≥ 2S + 1.
Для исправления всех ошибок кратности S и одновременного обнаружения всех ошибок кратности r d должно удовлетворять условию:
d ≥ r + S + 1.
Формулы для d приведены для случая взаимно независимых ошибок, дают завышенные значения d при помехе, коррелированной с сигналом.
В реальных каналах связи длительность импульсов помехи часто превышает длительность символа. При этом одновременно искажаются несколько расположенных рядом символов комбинации. Ошибки такого рода получили название пачек ошибок или пакетов ошибок. Длиной пачки ошибок называют число следующих друг за другом символов, начиная с первого искаженного символа и кончая последним искаженным символом, за которым следует не менее ρ неискаженных символов. Основой для выбора служат статистические данные об ошибках. Если, например, кодовая комбинация 00000000000000000 трансформировалась в комбинацию
и ρ принято равным трем, то в комбинации имеется два пакета длиной 4 и 5 символов.
Пример
Для пачек ошибок и асимметричного канала при той же корректирующей способности минимальное хэммингово расстояние между разрешенными комбинациями может быть меньше.
Подчеркнем еще раз, что каждый конкретный корректирующий код не гарантирует исправления любой комбинации ошибок. Коды предназначены для исправления комбинаций ошибок, наиболее вероятных для заданного канала и наиболее опасных по последствиям.
Если характер и уровень помехи отличаются от предполагаемых, эффективность применения кода резко снизится. http://peredacha-informacii.ru/ Применение корректирующего кода не может гарантировать безошибочного приема, но дает возможность повысить вероятность получения на выходе правильного результата.
Классические итеративные коды
Идея создания рассматриваемых кодов принадлежит П. Элайесу. Каждая из отдельных последовательностей информационных символов кодируется определенным линейным кодом (групповым или циклическим). Получаемый, таким образом, итеративный код так же является линейным. Простейший из таких кодов является двухстепенной (двумерный) код с проверкой на четность по строкам и столбцам, который широко используется на практике для обнаружения ошибок на магнитной ленте. Расположение информационных и проверочных символов приведено на рис. 8.1.
Значения проверочных символов, располагающихся в крайнем правом (или в любом другом) столбце и нижней строке, определяются уравнениями:
Передачу символов такого кода обычно осуществляют последовательно символ за символом, от одной строки к другой, либо параллельно целыми строками. Декодирование начинают сразу, не ожидая поступления всего блока информации. Проверка уравнений при декодировании позволяет обнаружить любое нечетное число искаженных символов, расположенных в одной строке или в одном столбце (рис. 8.2, б, в). Проверка одиночной ошибки по строке, указывает на наличие ошибки в ней, а проверка по столбцу – конкретный символ (рис. 8.2, а). Однако этим кодом не могут быть обнаружены ошибки, имеющие четное число искаженных символов, как по строкам, так и по столбцам.
Исправление при тройной ошибке соответствует внесению новой ошибки, вместо исправления старой (ложное исправление, рис. 8.2, г).
Простейшая не обнаруживаемая ошибка содержит четыре искаженных символа, расположенных в вершинах прямоугольника (рис. 8.2, д).
Число ошибок такого вида В4 для блока из l · n символов равно:
Общее число четырехкратных ошибок составляет:
Таким образом, отношение
При n = 8; l = 250 имеем:
Аналогичный расчет для шестикратных ошибок (рис. 8.3) типа
Минимальное кодовое расстояние итеративного кода равно:
где Dγ – кодовое расстояние линейного кода по координате γ.
Коррекция ошибок проводится последовательно. Сначала исправляют ошибки по одной координате, затем осуществляют исправление оставшихся ошибок по другой координате и т.д. http://peredacha-informacii.ru/ Такая процедура проста, но снижает корректирующую способность итеративного кода, поскольку оказывается невозможным исправить часть ошибок кратности (d – 1)/2.
Имеем два кода Хэмминга (7; 4).
Результирующий итеративный код (49; 16) имеет минимальное кодовое расстояние, равное 3 · 3 = 9, и, следовательно, потенциально, как любой линейный код, способен исправлять все ошибки кратности 4 и менее. Однако, применяя указанную выше процедуру декодирования, невозможно исправить четырехкратные ошибки с расположением искаженных символов в вершинах прямоугольника.
6.5.1. Весовой коэффициент двоичных векторов и расстояние между ними
6.5.2. Минимальное расстояние для линейного кода
6.5.3. Обнаружение и исправление ошибок
6.5.3.1. Распределение весовых коэффициентов кодовых слов
6.5.3.2. Одновременное обнаружение и исправление ошибок
6.5.4. Визуализация пространства 6-кортежей
6.5.5. Коррекция со стиранием ошибок
Весовой коэффициент двоичных векторов и расстояние между ними
Конечно же, понятно, что правильно декодировать можно не все ошибочные комбинации. Возможности кода для исправления ошибок в первую очередь определяются его структурой. Весовой коэффициент Хэмминга (Hamming weight) w(U) кодового слова U определяется как число ненулевых элементов в U. Для двоичного вектора это эквивалентно числу единиц в векторе. Например, если U=100101101, то w(U) = 5. Расстояние Хэмминга (Hamming distance) между двумя кодовыми словами U и V, обозначаемое как d(U, V), определяется как количество элементов, которыми они отличаются.
Согласно свойствам сложения по модулю 2, можно отметить, что сумма двух двоичных векторов является другим двоичным вектором, двоичные единицы которого расположены на тех позициях, которыми эти векторы отличаются.
U + V=111011001
Таким образом, можно видеть, что расстояние Хэмминга между двумя векторами равно весовому коэффициенту Хэмминга их суммы, т.е. d(U, V) = w(U + V). Также видно, что весовой коэффициент Хэмминга кодового слова равен его расстоянию Хэмминга до нулевого вектора.
Минимальное расстояние для линейного кода
Рассмотрим множество расстояний между всеми парами кодовых слой в пространстве Vn. Наименьший элемент этого множества называется минимальным расстоянием кода и обозначается dmin. Как вы думаете, почему нас интересует именно минимальное расстояние, а не максимальное? Минимальное расстояние подобно наиболее слабому звену в цепи, оно дает нам меру минимальных возможностей кода и, следовательно, характеризует его мощность.
Как обсуждалось ранее, сумма двух произвольных кодовых слов дает другой элемент пространства кодовых слов. Это свойство линейных кодов формулируется просто: если U и V — кодовые слова, то и W = U + V тоже должно быть кодовым словом. Следовательно, расстояние между двумя кодовыми словами равно весовому коэффициенту третьего кодового слова, т.е. d(U, V) = w(U + V) = w(W). Таким образом, минимальное расстояние линейного кода можно определить, не прибегая к изучению расстояний между всеми комбинациями пар кодовых слов. Нам нужно лишь определить вес каждого кодового слова (за исключением нулевого вектора) в подпространстве; минимальный вес соответствует минимальному расстоянию dmin. Иными словами, dmin соответствует наименьшему из множества расстояний между нулевым кодовым словом и всеми остальными кодовыми словами.
Обнаружение и исправление ошибок
Задача декодера после приема вектора r заключается в оценке переданного кодового слова Ui. Оптимальная стратегия декодирования может быть выражена в терминах алгоритма максимального правдоподобия (см. приложение Б); считается, что передано было слово Ui, если
Поскольку для двоичного симметричного канала (binary symmetric channel — BSC) правдоподобие Ui относительно r обратно пропорционально расстоянию между r и U, можно сказать, что передано было слово Ui, если
Другими словами, декодер определяет расстояние между r и всеми возможными переданными кодовыми словами Uj, после чего выбирает наиболее правдоподобное Uj, для которого
где М = 2k — это размер множества кодовых слов. Если минимум не один, выбор между минимальными расстояниями является произвольным. Наше обсуждение метрики расстояний будет продолжено в главе 7.
На рис. 6.13 расстояние между двумя кодовыми словами U и V показано как расстояние Хэмминга. Каждая черная точка обозначает искаженное кодовое слово. На рис. 6.13, а проиллюстрирован прием вектора r1 находящегося на расстоянии 1 от кодового слова U и на расстоянии 4 от кодового слова V. Декодер с коррекцией ошибок, следуя стратегии максимального правдоподобия, выберет при принятом векторе r1 кодовое слово U. Если r1 получился в результате появления одного ошибочного бита в переданном векторе кода U, декодер успешно исправит ошибку. Но если же это произошло в результате 4-битовой ошибки в векторе кода V, декодирование будет ошибочным. Точно так же, как показано на рис. 6.13, б, двойная ошибка при передаче U может привести к тому, что в качестве переданного вектора будет ошибочно определен вектор r2, находящийся на расстоянии 2 от вектора U и на расстоянии 3 от вектора кода V. На рис. 6.13 показана ситуация, когда в качестве переданного вектора ошибочно определен вектор r3, который находится на расстоянии 3 от вектора кода U и на расстоянии 2 от вектора V. Из рис. 6.13 видно, что если задача состоит только в обнаружении ошибок, а не в их исправлении, то можно определить искаженный вектор — изображенный черной точкой и представляющий одно-, двух-, трех- и четырехбитовую ошибку. В то же время пять ошибок при передаче могут привести к приему кодового слова V, когда в действительности было передано кодовое слово U; такую ошибку невозможно будет обнаружить.
Из рис. 6.13 можно видеть, что способность кода к обнаружению и исправлению ошибок связана с минимальным расстоянием между кодовыми словами. Линия решения на рисунке служит той же цели, что и в процессе демодуляции, — для разграничения областей решения.
Рис. 6.13. Возможности определения и исправления ошибок: а) принятый вектор r1; б) принятый вектор r2; в) принятый вектор r3
означает наибольшее целое, не превышающее х. Часто код, который исправляет все искаженные символы, содержащие ошибку в t или меньшем числе бит, также может исправлять символы, содержащие t+1 ошибочных бит. Это можно увидеть на рис. 6.11. В этом случае dmin = 3, поэтому из уравнения (6.44) можно видеть, что исправимы все ошибочные комбинации из t = 1 бит. Также исправима одна ошибочная комбинация, содержащая / +1 (т.е. 2) ошибочных бит. Вообще, линейный код (n, k), способный исправлять все символы, содержащие t ошибочных бит, может исправить всего 2n-k ошибочных комбинаций. Если блочный код с возможностью исправления символов, имеющих ошибки в t бит, применяется для исправления ошибок в двоичном симметричном канале с вероятностью перехода р, то вероятность ошибки сообщения Рм(вероятность того, что декодер совершит неправильное декодирование и п-битовый блок содержит ошибку) можно оценить сверху, используя уравнение (6.18).
В блочном коде, прежде чем исправлять ошибки, необходимо их обнаружить. ( Или же код может использоваться только для определения наличия ошибок.) Из рис. 6.13 видно, что любой полученный вектор, который изображается черной точкой (искаженное кодовое слово), можно определить как ошибку. Следовательно, возможность определения наличия ошибки дается следующим выражением.
Блочный код с минимальным расстоянием dmin гарантирует обнаружение всех ошибочных комбинаций, содержащих dmin – 1 или меньшее число ошибочных бит. Такой код также способен обнаружить и большую ошибочную комбинацию, содержащую dmin или более ошибок. Фактически код (n, k) может обнаружить 2n – 2k ошибочных комбинаций длины п. Объясняется это следующим образом. Всего в пространстве 2n n-кортежей существует 2n -1 возможных ненулевых ошибочных комбинаций. Даже правильное кодовое слово — это потенциальная ошибочная комбинация. Поэтому всего существует 2k -1 ошибочных комбинаций, которые идентичны 2k -1 ненулевым кодовым словам. При появлении любая из этих 2k – 1 ошибочных комбинаций изменяет передаваемое кодовое слово Uj на другое кодовое слово Uj. Таким образом, принимается кодовое слово Uj и его синдром равен нулю. Декодер принимает Uj за переданное кодовое слово, и поэтому декодирование дает неверный результат. Следовательно, существует 2k -1 необнаружимых ошибочных комбинаций. Если ошибочная комбинация не совпадает с одним из 2k кодовых слов, проверка вектора r с помощью синдромов дает ненулевой синдром и ошибка успешно обнаруживается. Отсюда следует, что существует ровно 2n-2k выявляемых ошибочных комбинаций. При больших n, когда 2k<<2n, необнаружимой будет только незначительная часть ошибочных комбинаций.
Распределение весовых коэффициентов кодовых слов
где р — вероятность перехода в двоичном симметричном канале. Если минимальное расстояние кода равно dmin значения от А1 до
, равны нулю.
Пример 6.5. Вероятность необнаруженной ошибки в коде
Пусть код (6,3), введенный в разделе 6.4.3, используется только для обнаружения наличия ошибок. Рассчитайте вероятность необнаруженной ошибки, если применяется двоичный симметричный канал, а вероятность перехода равна 10-2.
Распределение весовых коэффициентов этого кода выглядит следующим образом: A0=1, А1= А2 = 0, A3 = 4, A5 = 0, A6 = 0. Следовательно, используя уравнение (6.48), можно записать следующее.
Для р = 10-2 вероятность необнаруженной ошибки будет равна 3,9 х 10-6.
Одновременное обнаружение и исправление ошибок
При появлении t или меньшего числа ошибок код способен обнаруживать и исправлять их. Если ошибок больше t, но меньше е+1, где е определяется уравнением (6.47), код может определять наличие ошибок, но исправить может только некоторые из них. Например, используя код с dmin = 7. можно выполнить обнаружение и исправление со следующими значениями α и β.
Заметим, что исправление ошибки подразумевает ее предварительное обнаружение. В приведенном выше примере (с тремя ошибками) все ошибки можно обнаружить и исправить. Если имеется пять ошибок, их можно обнаружить, но исправить можно только одну из них.
Визуализация пространства 6-кортежей
На рис. 6.14 визуально представлено восемь кодовых слов, фигурирующих в примере из раздела 6.4.3. Кодовые слова образованы посредством линейных комбинаций из трех независимых 6-кортежей, приведенных в уравнении (6.26); сами кодовые слова образуют трехмерное подпространство. На рисунке показано, что такое подпространство полностью занято восемью кодовыми словами (большие черные круги); координаты подпространства умышленно выбраны неортогональными. На рис. 6.14 предпринята попытка изобразить все пространство, содержащее шестьдесят четыре 6-кортежей, хотя точно нарисовать или составить такую модель невозможно. Каждое кодовое слово окружают сферические слои или оболочки. Радиус внутренних непересекающихся слоев — это расстояние Хэмминга, равное 1; радиус внешнего слоя — это расстояние Хэмминга, равное 2. Большие расстояния в этом примере не рассматриваются. Для каждого кодового слова два показанных слоя заняты искаженными кодовыми словами. На каждой внутренней сфере существует шесть таких точек (всего 48 точек), представляющих шесть возможных однобитовых ошибок в векторах, соответствующих каждому кодовому слову. Эти кодовые слова с однобитовыми возмущениями могут быть соотнесены только с одним кодовым словом; следовательно, такие ошибки могут быть исправлены. Как видно из нормальной матрицы, приведенной на рис. 6.11, существует также одна двухбитовая ошибочная комбинация, которая также поддается исправлению. Всего существует
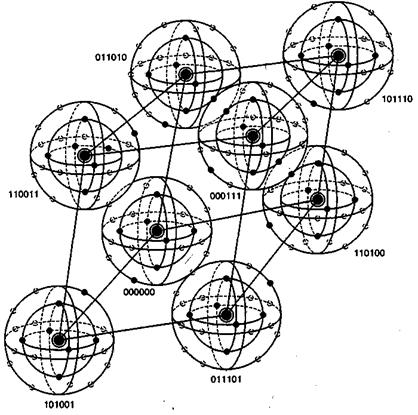
Рис, 6.14. Пример восьми кодовых слов в пространстве 6-кортежей
При представлении свойств класса кодов, известных как совершенные коды (perfect code), рис. 6.14 весьма полезен. Код, исправляющий ошибки в t битах, называется совершенным, если нормальная матрица содержит все ошибочные комбинации из t или меньшего числа ошибок и не содержит иных образующих элементов классов смежности (отсутствует возможность исправления остаточных ошибок). В контексте рис. 6.14 совершенный код с коррекцией ошибок в t битах — это такой код, который (при использовании обнаружения по принципу максимального правдоподобия) может исправить все искаженные кодовые слова, находящиеся на расстоянии Хэмминга t (или ближе) от исходного кодового слова, и не способен исправить ни одну из ошибок, находящихся на расстоянии, превышающем t.
Кроме того, рис. 6.14 способствует пониманию основной цели поиска хороших кодов. Предпочтительным является пространство, максимально заполненное кодовыми словами (эффективное использование введенной избыточности), а также желательно, чтобы кодовые слова были по возможности максимально удалены друг от друга. Очевидно, что эти цели противоречивы.
Коррекция со стиранием ошибок
Одновременное исправление ошибок и стираний можно осуществить следующим образом. Сначала позиции из у стираний замещаются нулями, и получаемое кодовое слово декодируется обычным образом. Затем позиции из у стираний замещаются единицами, и декодирование повторяется для этого варианта кодового слова. После обработки обоих кодовых слов (одно с подставленными нулями, другое — с подставленными единицами) выбирается то из них, которое соответствует наименьшему числу ошибок, исправленных вне позиций стирания. Если удовлетворяется неравенство (6.51), то описанный метод всегда дает верное декодирование.
Пример 6.6. Коррекция со стиранием ошибок
Рассмотрим набор кодовых слов, представленный в разделе 6.4.3.
000000 110100 011010 101110 101001 011101 110011 000111
Пусть передано кодовое слово 110011, в котором два крайних слева разряда приемник объявил стертыми. Проверьте, что поврежденную последовательность хx0011 можно исправить.
, код может исправить
= 2 стирания. В этом легко убедиться из рис. 6.11 или приведенного выше перечня кодовых слов, сравнивая 4 крайних правых разряда xx00l1 с каждым из допустимых кодовых слов. Действительно переданное кодовое слово — это ближайшее (с точки зрения расстояния Хэмминга) к искаженной последовательности.
Для
двоичного симметричного канала передачи
вероятность ошибочного приема любых
l
символов в n-элементной
кодовой комбинации подчиняется
биномиальному закону распределения
Неправильный
прием одного, двух, и т.д. элементов из
n-элементной
кодовой комбинации обозначают термином
«одиночная», «двойная» и т. д. ошибка
соответственно. Или говорят, что произошла
ошибка кратности l.
Если
код исправляет ошибки кратности t,
то вероятность ошибочного приема кодовой
комбинации равна
.
(4.4)
Пусть
исправляется ошибка кратности t=1.
Тогда из (4.4) для рассмотренного выше
примера (где n=8)
получим:
Исправление
всего лишь однократной ошибки повышает
помехоустойчивость
избыточного кода на два порядка.
Вопрос 30. Простейшие избыточные коды.
Код
с четным числом единиц. Код
с четным числом единиц образуется из
исходного k-элементного
кода добавлением еще одного элемента,
нуля или единицы, таким образом, чтобы
количество единиц в новой кодовой
комбинации было четным. Для определения
дополнительного элемента все элементы
исходной кодовой комбинации складывают
по модулю 2:
0
1 1 1 0 1 1 0 = 1,
0
0 1 1 0 1 1 0 = 0.
Таким
образом, число элементов в новой кодовой
комбинации n=k+r=k+1.
Избыточность кода с четным числом единиц
.
(4.5)
Этот
код имеет кодовое расстояние d=2
и обнаруживает все нечетные ошибки.
При
построении корреляционного кода каждый
элемент исходного кода преобразуется
в 2 элемента:
Таким
образом, корреляционный код относится
к непрерывным кодам.
Если
исходная комбинация содержит k
элементов, то новая кодовая комбинация
– n=2k.
Избыточность корреляционного кода
R=0,5
.
Помехоустойчивость
корреляционного кода обеспечивается
тем, что появление необнаруживаемой
ошибки возможно возможно только в
случае, когда два рядом стоящих элемента,
соответствующих одному элементу исходной
кодовой комбинации будут одновременно
искажены, то есть 1à0,
а 0à1.
Вероятность этого события
РНО=р2.
В корреляционном коде в линию связи
всегда передается одинаковое число 0 и
1, что обеспечивает эффективное
использование ее пропускной способности.
Вопрос 31. Групповой код Хемминга. Принципы построения. Синдром ошибки. Коды с обнаружением и исправлением ошибок. Код хемминга
7.1. Классификация корректирующих кодов
7.2. Принципы помехоустойчивого кодирования
7.3. Систематические коды
7.4. Код с четным числом единиц. Инверсионный код
7.5. Коды Хэмминга
7.6. Циклические коды
7.7. Коды с постоянным весом
7.8. Непрерывные коды
Классификация корректирующих кодов
В каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно.
Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность.
Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно.
Все известные в настоящее время коды могут быть разделены
на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
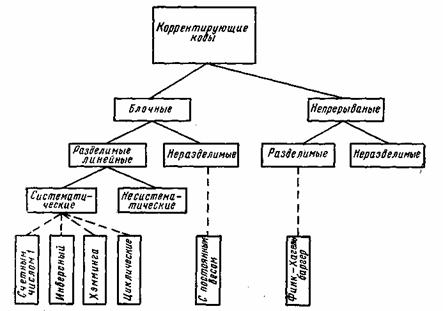
Рис. 7.1. Классификация корректирующих кодов
Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно.
Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов.