 (68 часов в уч. год)")

Вопросы и задания
В каких единицах измеряют скорость передачи данных?
2. Почему для любого канала связи скорость передачи данных ограничена?
3. Как вычисляется информационный объём данных, который можно передать за некоторое время?
4. В каких случаях при передаче данных допустимы незначительные ошибки?
5. Что такое избыточность сообщения? Для чего её можно использовать? Приведите примеры. Как помехи влияют на передачу данных?
7. Что такое бит чётности? В каких случаях с помощью бита чётности можно обнаружить ошибку, а в каких — нельзя?
8. Можно ли исправить ошибку, обнаружив неверное значение бита чётности?
9. Для чего используется метод вычисления контрольной суммы?
10. Какой код называют помехоустойчивым?
11. Каково должно быть расстояние Хэмминга между двумя любыми кодами, чтобы можно было исправить 2 ошибки?
12. Как исправляется ошибка при использовании помехоустойчивого кода?
13. Сколько ошибок обнаруживает 7-битный код Хэмминга, описанный в конце параграфа, и сколько ошибок он позволяет исправить?
а) «Алгоритмы CRC»
б) «Коды Хемминга»
Следующая страница Задачи
Cкачать материалы урока
Подсчет расстояния Хэмминга на большом наборе данных
Подобная задача является необычайно простой, но поиск ее эффективного решения до сих пор остается на повестке дня.
Расстояние Хэмминга уже довольно широко используется для различных задач, таких как поиск близких дубликатов, распознавание образов, классификация документов, исправление ошибок, обнаружения вирусов и т.
Описание проблемы
Имеется база данных бинарных строк T, размером n, где длина каждой строки m. Запрашиваемая строка a и требуемое расстояние Хэмминга k.
Задача сводится к поиску всех строк, которые находятся в пределах расстояния k.
В оригинальной концепции алгоритма рассматривается два варианта задачи: статическая и динамическая.
— В статической задачи расстояние k предопределено заранее. — В динамической, наоборот, требуемое расстояние заранее неизвестно.
В статье описывается решение только статической задачи.
Описание алгоритма HEngine для статической задачи
Данная реализация фокусируется на поиске строк в пределах k = ⌊k/2⌋ + 1 обязательно найдется, по крайней мере, q= r − ⌊k/2⌋ подстрок, когда их расстояние не будет превышать единицу, HD( ai, bi ) = ⌊k/2⌋ + 1
Длина первых r − (m mod r) подстрок будет иметь длину ⌊m / r⌋, а последние m mod r подстроки ⌈m/r⌉. Где m — это длина строки, ⌊ — округление до ближайшего снизу, а ⌉ округление до ближайшего сверху.
Теперь тоже самое, только на примере:
Даны две бинарные строки длиной m = 8 бит: A = 11110000 и B = 11010001, расстояние между ними k = 2. Выбираем фактор сегментации r = 2 / 2 + 1 = 2, т. всего будет 2 подстроки длиной m/r = 4 бита.
a1 = 1111, a2 = 0000 b1 = 1101, b2 = 0001
Если мы сейчас подсчитаем расстояние между соответствующими подстроками, то, по крайней мере, (q = 2 — 2/2 = 1) одна подстрока совпадет или их расстояние не будет превышать единицу.
Что и видим: HD( a1, b1 ) = HD( 1111, 1101 ) = 1 и HD( a2, b2 ) = HD( 0000, 0001 ) = 1
И главная идея алгоритма HEngine — это подготовить базу данных таким образом, чтобы найти совпадающие сигнатуры и затем выбрать те строки, которые находятся в пределах требуемого расстояния Хэмминга.
Предварительная обработка базы данных
Нам уже известно, что если правильно поделить строку на подстроки, то, по крайней мере, одна подстрока совпадет с соответствующей подстрокой либо количество отличающихся битов не будет превышать единицу (сигнатуры совпадут).
Это означает, что нам не надо проводить полный перебор по всем строкам из базы данных, а требуется сначала найти те сигнатуры, которые совпадут, т. подстроки будут отличаться максимум на единицу.
Но как производить поиск по подстрокам?
Метод двоичного поиска должен неплохо с этим справляться. Но он требует, чтобы список строк был отсортирован. Но у нас получается несколько подстрок из одной строки. Что бы произвести двоичный поиск по списку подстрок, надо чтобы каждый такой список был отсортирован заранее. Поэтому здесь напрашивается метод расширения базы данных, т. созданию нескольких таблиц, каждая для своей подстроки или сигнатуры. (Такая таблица называется таблицей сигнатур. А совокупность таких таблиц — набор сигнатур).
В оригинальной версии алгоритма еще описывается перестановка подстрок таким образом, чтобы выбранные подстроки были на первом месте. Это делается больше для удобства реализации и для дальнейших оптимизаций алгоритма:
Имеется строка A, которая делится на 3 подстроки, a1, a2, a3, полный список перестановок будет соответственно: a1, a2, a3 a2, a1, a3 a3, a1, a2
Затем эти таблицы сигнатур сортируются.
Реализация поиска
На этом этапе, после предварительной обработки базы данных мы имеем несколько копий отсортированных таблиц, каждая для своей подстроки.
Очевидно, что если мы хотим сперва найти подстроки, необходимо из запрашиваемой строки получить сигнатуры тем же способом, который был использован при создании таблиц сигнатур.
Так же нам известно, что необходимые подстроки отличаются максимум на один элемент. И чтобы найти их потребуется воспользоваться методом расширения запроса (query expansion).
А дальше производить двоичный поиск в соответствующей таблице сигнатур на полное совпадение.
Такие действия надо произвести для всех подстрок и для всех таблиц.
И в самом конце потребуется отфильтровать те строки, которые не вмещаются в заданный предел расстояния Хэмминга. произвести линейный поиск по найденным строкам и оставить только те строки, которые отвечают условию HD( a, b ) 11111111 1000 0001 => 10000001 0011 1110 => 00111110
Сортируем таблицы. Каждую в отдельности. Т1 0011 => 00111110 1000 => 10000001 1111 => 11111111
Т2 0001 => 10000001 1110 => 00111110 1111=> 11111111
На этом предварительная обработка закончена. И приступаем к поиску.
Получаем сигнатуры запрашиваемой строки. Искомая строка 10111110 разбивается на сигнатуры. Получается 1011 и 1100, соответственно первая для первой таблицы, а вторая для второй.
1 Для первой подстроки 1011: 1011 0011 1111 1001 1010
2 Для второй подстроки 1100: 1100 0100 1000 1110 1101
1 Для всех сгенерированных вариантов первой подстроки 1011 производим двоичный поиск в первой таблице на полное совпадение.
1011 0011 == 0011 => 00111110 1111 == 1111 => 11111111 1001 1010
Найдено две подстроки.
2 Теперь для всех вариантов второй подстроки 1100 производим двоичный поиск во второй таблице.
1100 0100 1000 1110 == 1110 => 00111110 1101
Найдена одна подстрока.
Объедением результаты в один список: 00111110 11111111
Линейно проверяем на соответствие и отфильтровываем неподходящие по условию
Расстояние Хэмминга
Установление степени сходства между текстами – задача, которая часто встречается в повседневной работе. В частности данный подход может пригодится при нечетком поиске, при работе с данными с возможными погрешностями(например, если данные «восстанавливаются» их распознанного документа или), а также при работе с персональными данными, качество которых, зачастую, зависит от человеческого фактора. Ранее мы уже рассматривали один из наиболее эффективных алгоритмов для сравнения двух последовательностей символов, применительно к возможным опечаткам в ФИО (расстояние Левенштейна — ссылка, схожество Джаро — Винклера — ссылка). Сегодня поговорим о другом способе вычисления редакционного расстояния и о кейсах, в которых он может быть наиболее применимым.
Один из самых простых подходов к вычислению дистанции между строками. Это число позиций, в которых соответствующие символы двух слов одинаковой длины различны. Изначально использовалось для определения меры различия между кодовыми комбинациями (двоичными векторами) в векторном пространстве кодовых последовательностей. Еще раз обратим внимание, что данный алгоритм применим только для строк одинаковой длины, при вычислении расстояния строки посимвольно сравниваются, и число «несовпадающих» символов и будет нашим результатом.
На языке программирования C# реализация будет выглядеть так:
Или с использование LINQ вот так:
Где можно применить данный алгоритм? Учитывая, что происходит банальное посимвольное сравнение, без учета операций перестановки, удаления, вставки символов, причем со строками одинаковой длины, данный алгоритм может пригодиться разве что при сравнении некоторых «условно-числовых» значений, которые могут встретиться среди персональных данных(например серия и номер паспорта, ИНН, номер счета, СНИЛС, номер водительского удостоверения), но даже при таком искусственном ограничении — не всегда. Рассмотрим пару кейсов:
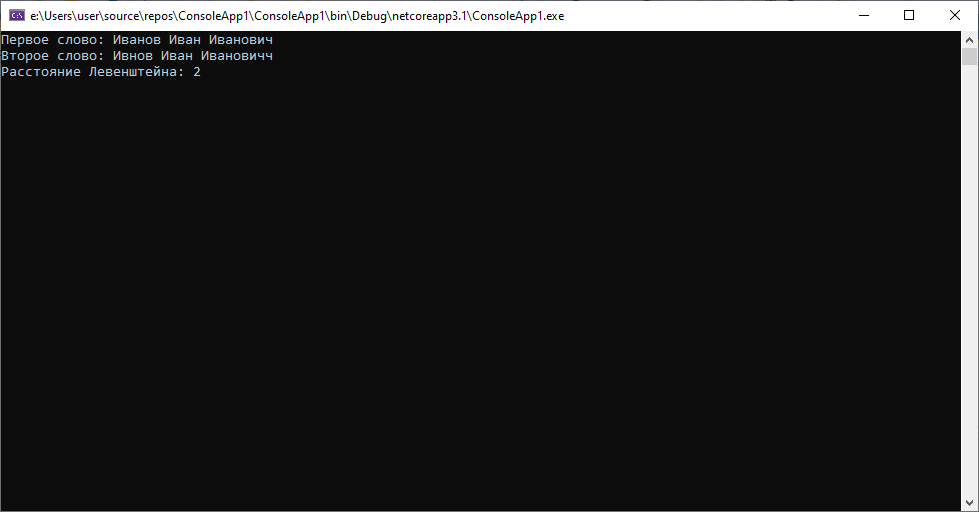
Паспортные данные клиентов 1234 567890 и 1244 567890, полученные из разных источников(допустим одни данные из автоматизированной системы, а вторые — распознанные данные со скана договора) для клиента Иванова Ивана Ивановича 01. 1990. Для такой ситуации расстояние будет следующим:
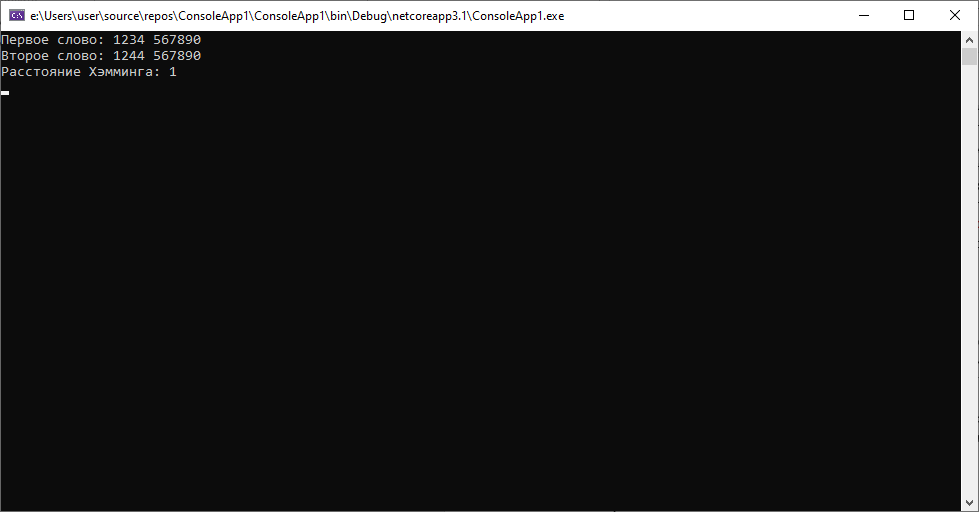
Как мы видим дистанция между строками небольшая, как и предполагалось, ведь они отличаются всего на один символ.
Предположим, что теперь наши данные таковы: 1234 567890 и 1243 567890(допустим, оба документа «пришли» к нам из разных автоматизированных систем). В данном случае алгоритм Хэмминга покажет следующее:
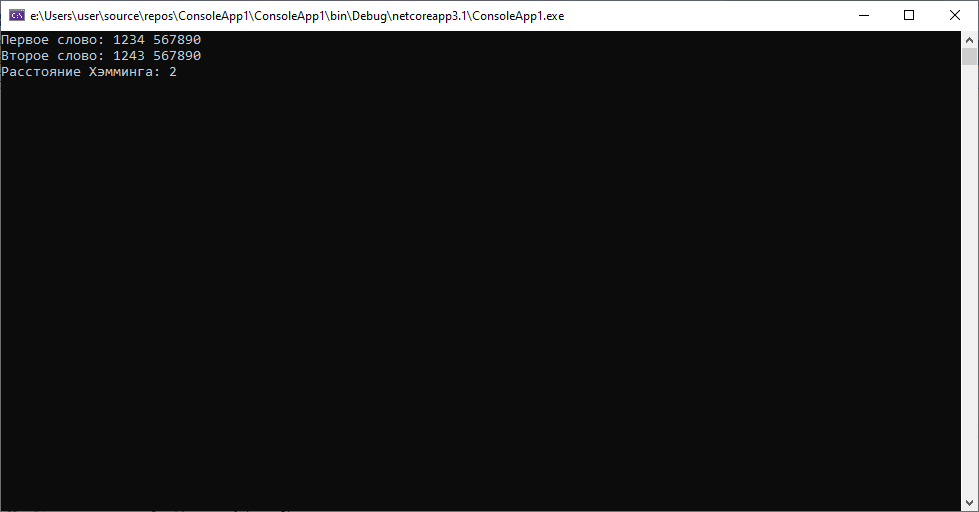
Здесь мы видим, что при минимальном различии(для нас очевидно, что в одном из случаев была «опечатка» — сотрудник неверно последовательно ввел 2 символа), расстояние уже будет равно 2. В то время, как при вычислении расстояния Левенштейна результат будет равен 1. Вывод: использование данного алгоритма для сравнения строк одинаковой длины возможно(и иногда уместно, учитывая простоту вычислений), но требует большего внимания при работе с данными, иногда расстояние может быть достаточно велико в случаях пропуска символов.
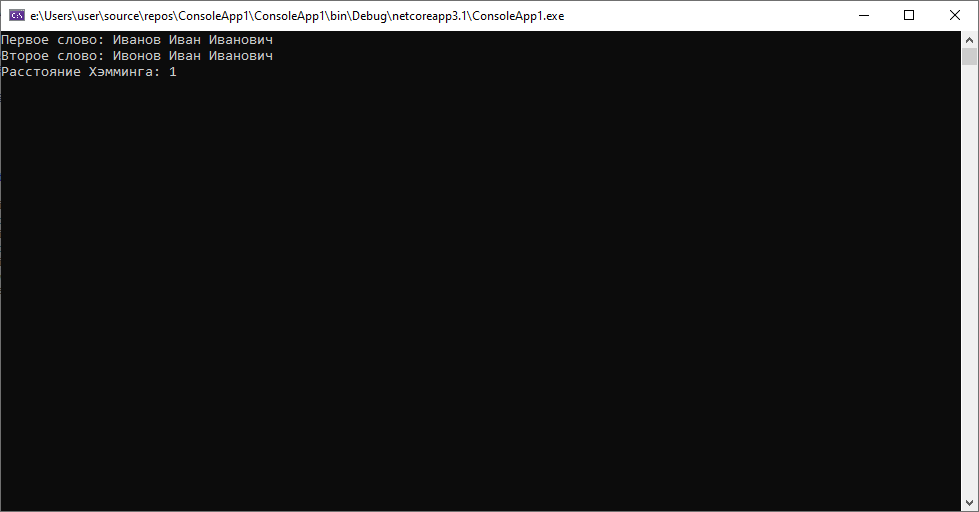
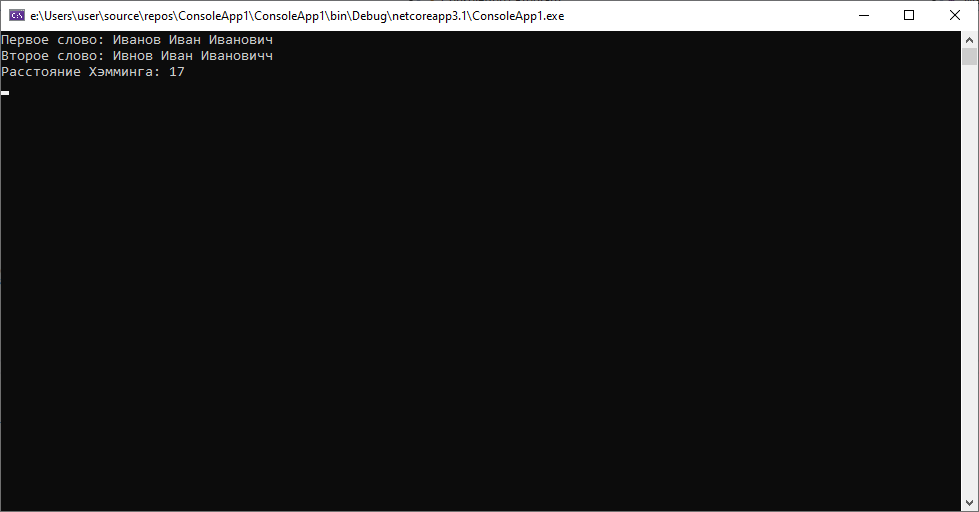
При этом расстояние Левенштейна во втором случае будет таковым.
Выводы: В случае работы с ФИО лучше использовать расстояние Левенштейна, не говоря уже о том, что строки могут быть по разным причинам не одинаковой длины. Однако в случае обработки значений заведомо фиксированной длины с небольшим количеством опечаток, расстояние Хэмминга может быть неплохим выбором для решения задачи.
Помехоустойчивое кодирование. Коды Хэмминга
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.
Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т. в любой системе передачи и хранении информации неизбежно возникают ошибки.
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.
Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
Возможен также гибридный вариант, чтобы лишний раз не гонять информацию по каналу связи, например получили пакет информации, попробовали его исправить, и если не смогли исправить, тогда отправляется запрос на повторную передачу.
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
Третий параметр, кратность исправляемых ошибок – количество ошибочных символов, которые код может исправить (обозначается буквой t).
Контроль чётности
Самый простой метод помехоустойчивого кодирования это добавление одного бита четности. Есть некое информационное сообщение, состоящее из 8 бит, добавим девятый бит.
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
Под кратностью понимается, всевозможные ошибки, которые можно обнаружить. В этом случае, кратность исправляемых ошибок 0, так как мы не можем исправить ошибки, а кратность обнаруживаемых 1.
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
Прямоугольный код – код с контролем четности, позволяющий исправить одну ошибку:
И если в процессе передачи информации допустим ошибку (ошибка нолик вместо единицы, желтым цветом), начинаем делать проверку. Нашли ошибку во втором столбце, третьей строке по координатам. Чтобы исправить ошибку, просто инвертируем 1 в 0, тем самым ошибка исправляется.
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
Рассчитаем скорость кода для:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
Классификация помехоустойчивых кодов
По используемому алфавиту:
Блочные коды делятся на
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.
Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.
Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:
Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:
Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)
Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.
Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
Компромиссы при использовании помехоустойчивых кодов
Чем расплачиваемся за помехоустойчивые коды? Добавили избыточность, соответственно эту избыточность тоже нужно передавать. Нужно: увеличивать пропускную способность канала связи, либо увеличивать длительность передачи.
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
Например, в канале связи шумов мало, все передается хорошо, ошибки возникают редко, но вдруг возникла импульсная помеха или замирания, которые повредили на некоторое время процесс передачи, и потерялся большой кусок информации. В среднем на блок приходится одна, две ошибки, а в нашем примере потерялся целый блок, включая информационные и проверочные биты. Сможет ли помехоустойчивый код исправить такую ошибку? Эта проблема решаема за счет перемежения.
Пример блочного перемежения:
На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.
Расстояние Хемминга
Расстояние Хэмминга — мера (точнее, метрика) различия объектов одинаковой размерности.
Первоначально метрика была сформулирована Ричардом Хэммингом во время его работы в Bell Labs для определения меры различия между кодовыми комбинациями (двоичными векторами) в векторном пространстве кодовых последовательностей, в этом случае расстоянием Хэмминга между двумя двоичными последовательностями (векторами) и длины называется число позиций, в которых они различны — в такой формулировке расстояние Хэмминга вошло в Словарь алгоритмов и структур данных Национального Института Стандартов США (англ. NIST Dictionary of Algorithms and Data Structures ).
Так, расстояние Хэмминга между векторами 0 01 1 1 и 1 01 0 1 равно 2 (красным отмечены различающиеся биты). В дальнейшем метрика была обобщена на q-ичные последовательности: для пары строк « вы бор ы » и « за бор а » расстояние Хэмминга равно трём.
В общем виде расстояние Хэмминга для объектов и размерности задаётся функцией:
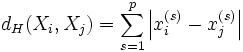
Расстояние Хэмминга обладает свойствами метрики, удовлетворяя следующим условиям:
Расстояние Хэмминга в биоинформатике и геномике
При эволюционном расхождении гомологичных ДНК-последовательностей расстояние Хэмминга является мерой, по которой можно судить о времени, прошедшем с момента расхождения гомологов, например, о длительности эволюционного отрезка, разделяющего гены-гомологи и ген-предшественник.
Ссылки
§ 2. Передача данных
В каких единицах измеряют скорость передачи данных?2. Почему для любого канала связи скорость передачи данных ограничена?3. Как вычисляется информационный объём данных, который можно передать за некоторое время?4. В каких случаях при передаче данных допустимы незначительные ошибки?5. Что такое избыточность сообщения? Для чего её можно использовать? Приведите примеры. Как помехи влияют на передачу данных?7. Что такое бит чётности? В каких случаях с помощью бита чётности можно обнаружить ошибку, а в каких — нельзя?8. Можно ли исправить ошибку, обнаружив неверное значение бита чётности?9. Для чего используется метод вычисления контрольной суммы?10. Какой код называют помехоустойчивым?11. Каково должно быть расстояние Хэмминга между двумя любыми кодами, чтобы можно было исправить 2 ошибки?12. Как исправляется ошибка при использовании помехоустойчивого кода?13. Сколько ошибок обнаруживает 7-битный код Хэмминга, описанный в конце параграфа, и сколько ошибок он позволяет исправить?
а) «Алгоритмы CRC»б) «Коды Хемминга»
Через соединение со скоростью 128 000 бит/с передают файл размером 625 Кбайт. Определите время передачи файла в секундах.
Передача файла через соединение со скоростью 512 000 бит/с заняла 1 минуту. Определите размер файла в килобайтах.
Скорость передачи данных равна 64 000 бит/с. Сколько времени займёт передача файла объёмом 375 Кбайт по этому каналу?
У Васи есть доступ к Интернету по высокоскоростному одностороннему радиоканалу, обеспечивающему скорость получения им информации 256 000 бит/с. У Пети нет скоростного доступа к Интернету, но есть возможность получать информацию от Васи по низкоскоростному телефонному каналу со средней скоростью 32 768 бит/с. Петя договорился с Васей, что тот будет скачивать для него данные объёмом 5 Мбайт по высокоскоростному каналу и ретранслировать их Пете по низкоскоростному каналу. Компьютер Васи может начать ретрансляцию данных не раньше, чем им будут получены первые 375 Кбайт этих данных. Каков минимально возможный промежуток времени (в секундах) с момента начала скачивания Васей данных до полного их получения Петей?
Определите максимальный размер файла в килобайтах, который может быть передан за 8 минут со скоростью 32 000 бит/с.
Сколько секунд потребуется, чтобы передать 400 страниц текста, состоящего из 30 строк по 60 символов каждая по линии со скоростью 128 000 бит/с, при условии что каждый символ кодируется 1 байтом?
Передача текстового файла по каналу связи со скоростью 128 000 бит/с заняла 1,5 мин. Определите, сколько страниц содержал переданный текст, если известно, что он был представлен в 16-битной кодировке UNICODE, а на одной странице — 400 символов.
Передача текстового файла через соединение со скоростью 64 000 бит/с заняла 10 с. Определите, сколько страниц содержал переданный текст, если известно, что он был представлен в 16-битной кодировке UNICODE и на каждой странице — 400 символов.
Сколько секунд потребуется, чтобы передать цветное растровое изображение размером 1280 х 800 пикселей по линии со скоростью 256 000 бит/с при условии, что цвет каждого пикселя кодируется 24 битами?
Сколько секунд потребуется, чтобы передать цветное растровое изображение размером 1000 х 800 пикселей по линии со скоростью 128 000 бит/с при условии, что цвет каждого пикселя кодируется 24 битами?
Через некоторый канал связи за 2 минуты был передан файл, размер которого — 3750 Кбайт. Определите минимальную скорость, при которой такая передача возможна.
12*. Модем, передающий информацию со скоростью 256 000 бит/с, передал файл с несжатой стереофонической музыкой за 2 минуты 45 секунд. Найдите разрядность кодирования этой музыки, если известно, что её продолжительность составила 1 минуту и оцифровка производилась с частотой 22 000 Гц.
Найдите расстояние между кодами 11101 и 10110, YUIX и YAIY.
Найдите все пятизначные двоичные коды, расстояние от которых до кода 11101 равно 1. Сколько всего может быть таких слов для «-битного кода?
Для передачи восьмеричных чисел используется помехоустойчивый шестибитный код, приведённый в тексте параграфа. Раскодируйте сообщение, исправив ошибки:
Добрый день, дорогие форумчане! Прошу помощи.
Перевод десятичного числа в байтыВсем доброе время суток! Пишу драйвера для принтера чеков под linux. не могу найти ответа на.
Передача пакета устройствуЗдравствуйте. Простите за банальный вопрос, но объясните пожалуйста или киньте ссылку на подробный.
Перевод битов в байтыпомогите сделать цикл для перевода битов в байты. имеется массив битов одномерный. при помощи.
Перевод битов в байтывсем приветик. пшу прогу просомторщика который переводит байты (символы) в бинарный вид и.
Перевод килобайт в байтыЗдравствуйте. Извените за беспокойство у меня возникла проблемка,мне до завтрешнего дня надо здать.
Помощь в написании контрольных, курсовых и дипломных работ здесь.

Перевод переменной в байты Python 2. 7Добрый день. Есть скрипт, принимающий несколько параметров при запуске. один из параметров.
Перевести числа в байтыКак превратить число (1234567) в строку с байтами? Т. ‘4V’, а не b’1234567′. Мне.
001 101 011 011 011 101 110 101 101 011
Следующая страница §2. Передача информации
Cкачать материалы урока
Скорость передачи данных равна 64 000 бит/с. Сколько времени займет передача файла объемом 375 Кбайт по этому каналу?
У Васи есть доступ к Интернету по высокоскоростному одностороннему радиоканалу, обеспечивающему скорость получения им информации 256 000 бит/с. У Пети нет скоростного доступа к Интернету, но есть возможность получить информацию от Васи по низкоскоростному телефонному каналу со средней скоростью 32 768 бит/с. Петя договорился с Васей, что тот будет скачивать для него данные объемом 5 Мбайт по высокоскоростному каналу и ретранслировать их Пете по низкоскоростному каналу. Компьютер Васи может начать ретрансляцию данных не раньше, чем им будут получены первые 375 Кбайт этих данных. Каков минимально возможный промежуток времени (в секундах) с момента начала скачивания Васей данных до полного их получения Петей?
Сколько секунд потребуется, чтобы передать цветное растровое изображение размером 1280 × 800 пикселей по линии со скоростью 256 000 бит/с при условии, что цвет каждого пикселя кодируется 24 битами?
Сколько секунд потребуется, чтобы передать цветное растровое изображение размером 1000 × 800 пикселей по линии со скоростью 128 000 бит/с при условии, что цвет каждого пикселя кодируется 24 битами?
*12. Модем, передающий информацию со скоростью 256 000 бит/с, передал файл с несжатой стереофонической музыкой за 2 минуты 45 секунд. Найдите разрядность кодирования этой музыки, если известно, что ее продолжительность составила 1 минуту и оцифровка производилась с частотой 22 000 Гц.
Найдите все пятизначные двоичные коды, расстояние от которых до конца 11101 равно 1. Сколько всего может быть таких слов для n-битного кода?
Значительно сложнее исправить ошибку сразу (без повторной передачи), однако в некоторых случаях и эту задачу удаётся решить. Для этого требуется настолько увеличить избыточность кода (добавить «лишние» биты), что небольшое число ошибок всё равно позволяет достаточно уверенно распознать переданное сообщение. Например, несмотря на помехи в телефонной линии, обычно мы легко понимаем собеседника. Это значит, что речь обладает достаточно большой избыточностью, и это позволяет исправлять ошибки «на ходу».
Пусть, например, нужно передать один бит, 0 или 1. Утроим его, добавив ещё два бита, совпадающих с первым. Таким образом, получаются два «правильных» сообщения:
000 и 111.
Теперь посмотрим, что получится, если при передаче одного из битов сообщения 000 произодёт ошибка и приёмник получит искажённое сообщение 001. Заметим, что оно отличается одним битом от ООО и двумя битами от второго возможного варианта — 111. Значит, скорее всего, произошла ошибка в последнем бите и сообщение нужно исправить на 000. Если приёмник получил 101, можно точно сказать, что произошла ошибка, однако попытка исправить её приведёт к неверному варианту, так как ближайшая «правильная» последовательность — это 111. Таким образом, такой код обнаруживает одну или две ошибки. Кроме того, он позволяет исправить (!) одну ошибку, т. является помехоустойчивым.
Помехоустойчивый код — это код, который позволяет исправлять ошибки, если их количество не превышает некоторого уровня.
Выше мы фактически применили понятие «расстояния» между двумя кодами. В теории передачи информации эта величина называется расстоянием Хэмминга в честь американского математика Р. Хэмминга.
Расстояние Хэмминга — это количество позиций, в которых различаются два закодированных сообщения одинаковой длины.
Например, расстояние d между кодами 001 и 100 равно
потому что они различаются в двух битах (эти биты подчёркнуты). В приведённом выше примере расстояние между «правильными» последовательностями (словами) равно d(000, 111) = 3. Такой код позволяет обнаружить одну или две ошибки и исправить одну ошибку.
В общем случае, если минимальное расстояние между «правильными» словами равно d, можно обнаружить от 1 до d – 1 ошибок, потому что при этом полученный код будет отличаться от всех допустимых вариантов. Для исправления г ошибок необходимо, чтобы выполнялось условие
d ≥ 2r +1.
Это значит, что слово, в котором сделано г ошибок, должно быть ближе к исходному слову (из которого оно получено искажением), чем к любому другому.
Рассмотрим более сложный пример. Пусть нужно передавать три произвольных бита, обеспечив обнаружение двух любых ошибок и исправление одной ошибки. В этом случае можно использовать, например, такой код с тремя контрольными битами (они подчёркнуты):
Расстояние Хэмминга между любыми двумя словами в таблице не менее 3, поэтому код обнаруживает две ошибки и позволяет исправить одну. Как же вычислить ошибочный бит?
Предположим, что было получено кодовое слово 011011. Определив расстояние Хэмминга до каждого из «правильных» слов, находим единственное слово 010011, расстояние до которого равно 1 (расстояния до остальных слов больше). Значит, скорее всего, это слово и было передано, но исказилось из-за помех.
На практике используют несколько более сложные коды, которые называются кодами Хэмминга. В них информационные и контрольные биты перемешаны, и за счёт этого можно сразу, без перебора, определить номер бита, в котором произошла ошибка. Наиболее известен семибитный код, в котором 4 бита — это данные, а 3 бита — контрольные. В нём минимальное расстояние между словами равно 3, поэтому он позволяет обнаружить две ошибки и исправить одну.
Следующая страница Вопросы и задания

Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
- где n – количество символов закодированного сообщения (результата кодирования);
- m – количество проверочных символов, добавляемых при кодировании;
- k – количество информационных символов.
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.

- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
- Систематические — отдельно не измененные информационные символы, отдельно проверочные символы. Если на входе кодера присутствует блок из k символов, и в процессе кодирования сформировали еще какое-то количество проверочных символов и проверочные символы ставим рядом к информационным в конец или в начало. Выходной блок на выходе кодера будет состоять из информационных символов и проверочных.
- Несистематические — символы исходного сообщения в явном виде не присутствуют. На вход пришел блок k, на выходе получили блок размером n, блок на выходе кодера не будет содержать в себе исходных данных.







- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.


- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания

Вес Хэмминга
Вес Хэмминга символьной строки определяется как число символов других , чем нулевой символ из алфавита , используемого. Это также расстояние Хэмминга до нулевого вектора (символьная строка такой же длины, которая состоит только из нулевых символов).
Расстояние Хэмминга кода
Расстояние Хэмминга кода – это минимум всех расстояний между разными словами в коде.
Код состоит из следующих трех слов:
Расстояние Хэмминга между и равно 2. Для генерации вам необходимо изменить два бита (первый и второй бит справа налево): Расстояние Хэмминга между и равно 1. Для генерации нужно изменить один бит (четвертый):Расстояние Хэмминга между и равно 3. Для генерации необходимо изменить три бита:
Наименьшее из трех расстояний равно 1, поэтому расстояние Хэмминга кода также равно 1.
Расстояние Хэмминга важно, если вы хотите разработать коды, которые позволяют обнаруживать ошибки ( EDC ) или исправлять ( ECC ).
В случае кодов с расстоянием Хэмминга могут быть обнаружены все -битовые ошибки. В примере с не может быть обнаружена даже каждая 1-битная ошибка (x↔z не замечается, все другие 1-битные ошибки генерируют недопустимые коды, например, 00111 из x или y).
Для каждой 1-битной ошибки может быть обнаружена. Для того, чтобы также иметь возможность исправлять ошибки, расстояние Хэмминга должно быть увеличено по крайней мере до , где обозначает количество исправляемых битовых ошибок.
С помощью можно распознать и исправить все однобитовые ошибки. Если возникают 2-битные ошибки, они могут быть неправильно «исправлены», поскольку неправильное слово может находиться на расстоянии 1 от другого допустимого кодового слова.
С помощью также можно распознать и исправить все однобитовые ошибки. Если возникают 2-битные ошибки, их можно распознать, но больше не исправить.
Расстояние Хэмминга кода обязательно является натуральным положительным числом. Код с расстоянием Хэмминга 0 невозможен, потому что в этом случае невозможно различить два кодовых слова.
Нахождение расстояния Хэмминга кода
Ручное определение лучше всего проводить с помощью диаграммы Карно-Вейча. Здесь вы вводите крестик для каждого встречающегося значения кода. Если имеется хотя бы два креста, расположенных непосредственно рядом друг с другом по горизонтали или вертикали, с совпадающими противоположными краями, расстояние Хэмминга = 1. Смежная диаграмма Карно-Вейча для 4 бит (серые поля – циклические повторения) показывает расстояние между значением кода и заданным (крестиком). Так что вы можете z. признать, что с 4 битами есть только два значения с расстоянием Хэмминга = 4, а именно дополнительная пара.
В двоичном коде расстояние Хэмминга между двумя кодовыми словами может и теми, которые указаны в результате, определяется (XOR b) и подсчетом.