

Коды состояния ответа HTTP указывают, был ли успешно завершен конкретный HTTP-запрос.
Ответы сгруппированы в пять классов:
Перечисленные ниже коды состояния определены в RFC 9110.
Примечание. Если вы получили ответ, которого нет в этом списке, это нестандартный ответ, возможно, настроенный для программного обеспечения сервера.
Информационные ответы
Этот промежуточный ответ указывает, что клиент должен продолжить запрос или игнорировать ответ, если запрос уже завершен.
101 протокол коммутации
Этот код отправляется в ответ на заголовок запроса на обновление от клиента и указывает протокол, на который переключается сервер.
102 Обработка (WebDAV)
Этот код указывает, что сервер получил и обрабатывает запрос, но ответа пока нет.
103 Ранние подсказки
Успешные ответы
Запрос выполнен успешно. Значение результата «успех» зависит от метода HTTP:
Запрос выполнен успешно, и в результате был создан новый ресурс. Обычно это ответ, отправляемый после запросов POST или некоторых запросов PUT.
Запрос получен, но еще не обработан.
Это ни к чему не обязывает, поскольку в HTTP нет возможности позже отправить асинхронный ответ, указывающий результат запроса.
Он предназначен для случаев, когда запрос обрабатывается другим процессом или сервером, или для пакетной обработки.
Этот код ответа означает, что возвращенные метаданные не совсем совпадают с доступными с исходного сервера, а собираются из локальной или сторонней копии.
Чаще всего это используется для зеркал или резервных копий другого ресурса.
За исключением этого конкретного случая, ответ 200 OK предпочтительнее этого статуса.
204 Нет содержания
205 Сбросить содержимое
206 Частичное содержимое
Этот код ответа используется, когда заголовок Range отправляется от клиента для запроса только части ресурса.
207 Мультистатус (WebDAV)
Передает информацию о нескольких ресурсах для ситуаций, когда могут быть уместны несколько кодов состояния.
208 Уже сообщалось (WebDAV)
226 Использовано IM (HTTP-дельта-кодирование)
Сервер выполнил запрос GET для ресурса, и ответ представляет собой представление результата одной или нескольких манипуляций с экземпляром, примененных к текущему экземпляру.
Сообщения о перенаправлении
300 вариантов выбора
301 Переехали навсегда
URL-адрес запрошенного ресурса был изменен навсегда. Новый URL-адрес указан в ответе.
Этот код ответа означает, что URI запрошенного ресурса был временно изменен.
В будущем могут быть внесены дальнейшие изменения в URI. Следовательно, этот же URI должен использоваться клиентом в будущих запросах.
303 См. прочее
Сервер отправил этот ответ, чтобы указать клиенту получить запрошенный ресурс по другому URI с помощью запроса GET.
304 Не изменено
Используется для целей кэширования.
Он сообщает клиенту, что ответ не был изменен, поэтому клиент может продолжать использовать ту же кэшированную версию ответа.
305 Использовать прокси
Определено в предыдущей версии спецификации HTTP, чтобы указать, что запрошенный ответ должен быть доступен через прокси.
Он устарел из-за проблем безопасности, связанных с внутренней настройкой прокси-сервера.
Этот код ответа больше не используется; это просто зарезервировано. Он использовался в предыдущей версии спецификации HTTP/1.1.
307 Временное перенаправление
308 Постоянное перенаправление
400 Неверный запрос
Сервер не может или не будет обрабатывать запрос из-за чего-то, что воспринимается как ошибка клиента (например, неправильный синтаксис запроса, неверный кадр сообщения запроса или обманная маршрутизация запроса).
Хотя стандарт HTTP определяет «неавторизованный», семантически этот ответ означает «неаутентифицированный».
То есть клиент должен аутентифицировать себя, чтобы получить запрошенный ответ.
402 Требуется оплата
Этот код ответа зарезервирован для использования в будущем.
Первоначальной целью создания этого кода было использование его для цифровых платежных систем, однако этот код состояния используется очень редко, и стандартного соглашения не существует.
Клиент не имеет прав доступа к контенту; то есть он неавторизован, поэтому сервер отказывается предоставить запрошенный ресурс.
В отличие от 401 Unauthorized, личность клиента известна серверу.
404 Не найден
Сервер не может найти запрошенный ресурс.
В браузере это означает, что URL-адрес не распознан.
В API это также может означать, что конечная точка действительна, но сам ресурс не существует.
Серверы также могут отправить этот ответ вместо 403 Forbidden, чтобы скрыть существование ресурса от неавторизованного клиента.
Этот код ответа, вероятно, наиболее известен из-за его частого появления в сети.
405 Метод не разрешен
Метод запроса известен серверу, но не поддерживается целевым ресурсом.
Например, API может не разрешать вызов DELETE для удаления ресурса.
406 Неприемлемо
407 Требуется аутентификация прокси
Это похоже на 401 Unauthorized, но аутентификация должна выполняться через прокси.
408 Таймаут запроса
Некоторые серверы отправляют этот ответ при бездействующем соединении даже без предварительного запроса со стороны клиента.
Это означает, что сервер хотел бы закрыть это неиспользуемое соединение.
Этот ответ используется гораздо чаще, поскольку некоторые браузеры, такие как Chrome, Firefox 27+ или IE9, используют механизмы предварительного подключения HTTP для ускорения серфинга.
Также обратите внимание, что некоторые серверы просто отключают соединение, не отправляя это сообщение.
Этот ответ отправляется, когда запрос конфликтует с текущим состоянием сервера.
Этот ответ отправляется, когда запрошенный контент был окончательно удален с сервера без адреса пересылки.
Ожидается, что клиенты удалят свои кеши и ссылки на ресурс.
Спецификация HTTP предполагает, что этот код состояния будет использоваться для «ограниченных по времени рекламных услуг».
API не должны чувствовать себя обязанными указывать ресурсы, которые были удалены, с помощью этого кода состояния.
Требуемая длина 411
Сервер отклонил запрос, поскольку поле заголовка Content-Length не определено и оно требуется серверу.
412 Предварительное условие не выполнено
Клиент указал в своих заголовках предварительные условия, которым сервер не соответствует.
413 Полезная нагрузка слишком велика
Объект запроса превышает пределы, определенные сервером.
Сервер может закрыть соединение или вернуть поле заголовка Retry-After.
414 Слишком длинный URI
URI, запрошенный клиентом, длиннее, чем сервер готов интерпретировать.
415 Неподдерживаемый тип носителя
Медиа-формат запрошенных данных не поддерживается сервером, поэтому сервер отклоняет запрос.
416 Диапазон неудовлетворителен
Диапазон, указанный в поле заголовка Range в запросе, не может быть заполнен.
Возможно, диапазон выходит за пределы размера данных целевого URI.
417 Ожидание не оправдалось
Этот код ответа означает, что ожидание, указанное в поле заголовка запроса Expect, не может быть удовлетворено сервером.
418 Я чайник
Официант отклоняет попытку заварить кофе в чайнике.
421 Неверно направленный запрос
Запрос был направлен на сервер, который не может дать ответ.
Его может отправить сервер, который не настроен на выдачу ответов для комбинации схемы и полномочий, включенных в URI запроса.
422 Необработанный контент (WebDAV)
423 Заблокировано (WebDAV)
Ресурс, к которому осуществляется доступ, заблокирован.
424 Неудачная зависимость (WebDAV)
Запрос не выполнен из-за сбоя предыдущего запроса.
425 Слишком рано
Указывает, что сервер не желает рисковать обработкой запроса, который может быть воспроизведен.
426 Требуется обновление
Сервер отказывается выполнять запрос с использованием текущего протокола, но может быть готов сделать это после того, как клиент перейдет на другой протокол.
Сервер отправляет заголовок Upgrade в ответе 426, чтобы указать требуемый протокол(ы).
428 Требуется предварительное условие
Исходный сервер требует, чтобы запрос был условным.
Этот ответ предназначен для предотвращения проблемы «потерянного обновления», когда клиент ПОЛУЧАЕТ состояние ресурса, изменяет его и отправляет обратно на сервер, в то время как третья сторона изменила состояние на сервере, что привело к конфликту.
429 Слишком много запросов
Сервер не желает обрабатывать запрос, поскольку поля его заголовка слишком велики.
Запрос может быть отправлен повторно после уменьшения размера полей заголовка запроса.
451 Недоступно по юридическим причинам
500 Внутренняя ошибка сервера
Сервер столкнулся с ситуацией, с которой не знает, как справиться.
501 Not Implemented
The request method is not supported by the server and cannot be handled. The only methods that servers are required to support (and therefore that must not return this code) are GET and HEAD.
502 Bad Gateway
This error response means that the server, while working as a gateway to get a response needed to handle the request, got an invalid response.
503 Service Unavailable
504 Gateway Timeout
This error response is given when the server is acting as a gateway and cannot get a response in time.
505 HTTP Version Not Supported
The HTTP version used in the request is not supported by the server.
506 Variant Also Negotiates
The server has an internal configuration error: the chosen variant resource is configured to engage in transparent content negotiation itself, and is therefore not a proper end point in the negotiation process.
507 Insufficient Storage (WebDAV)
The method could not be performed on the resource because the server is unable to store the representation needed to successfully complete the request.
508 Loop Detected (WebDAV)
The server detected an infinite loop while processing the request.
510 Not Extended
Further extensions to the request are required for the server to fulfill it.
511 Network Authentication Required
Indicates that the client needs to authenticate to gain network access.
Browser compatibility
BCD tables only load in the browser
See also
Написать HTML — здорово, но как понять, где ошибка, когда что-то не работает? В этой статье описаны несколько инструментов, которые помогают искать и исправлять ошибки в HTML.
Отладка — это не страшно
Во время написания какого-нибудь кода, обычно все идёт хорошо, пока не появляется тот момент, когда вы совершаете ошибку. Итак, ваш код не работает, или работает не так, как вы задумывали. Если вы попытаетесь скомпилировать неработающую программу на языке Rust, компилятор укажет на ошибку:
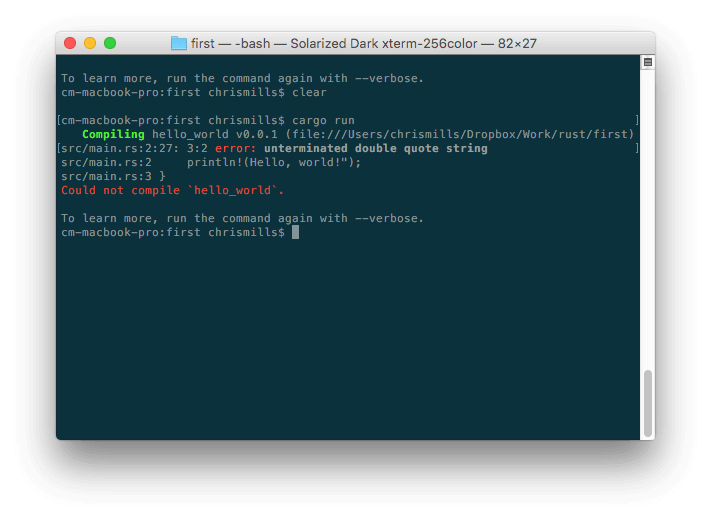
В данном случае, сообщение об ошибке понять относительно просто — “unterminated double quote string”. Если вы внимательно посмотрите на println!(Hello, world!”); , то заметите, что здесь отсутствует двойная кавычка. Разумеется, сообщения об ошибках могут становиться куда более сложными для понимания по мере роста вашего кода, и даже самые простые случаи могут показаться пугающими для тех, кто ничего не знает о Rust.
Но не бойтесь отладки! Чтобы комфортно писать и отлаживать любой код, нужно понимать язык и его инструменты.
HTML и отладка
HTML не так сложен к пониманию, как Rust. H TML не компилируется в какую-либо другую форму перед тем, как браузер проанализирует это и покажет результат (он является интерпретируемым, а не компилируемым). Синтаксис HTML элементов намного понятнее, чем у “настоящих языков программирования”, таких как Rust, JavaScript, или Python (en-US). Способ, которым браузеры читают HTML более толерантен, чем у языков программирования, интерпретирующих свой код строже. Это одновременно и плохо, и хорошо.
Толерантный код
Так что же означает толерантный? В общих чертах, когда вы напортачили в коде, есть два типа ошибок, с которыми вы столкнётесь:
HTML не страдает от синтаксических ошибок, потому что браузер читает код толерантно, в том смысле, что страницы могут отображаться даже если синтаксические ошибки присутствуют. Браузеры имеют встроенные правила по интерпретации неверно написанной разметки, и вы можете запустить что-либо, даже если вы имели в виду другое. Это может стать настоящей проблемой!
Примечание: HTML читается толерантно, потому что когда веб только появился, было решено позволить людям публиковать контент даже при условии некорректностей в коде, так как это куда более важно, чем уверенность в абсолютно верном синтаксисе. Веб не был бы сейчас так популярен, если бы относился к новичкам строго.
Знакомство с толерантным кодом
Время изучить природу толерантного кода в HTML.
Валидация HTML
Из примера выше ясно, что стоит проверять валидность HTML. В простом примере сверху можно просто просмотреть весь код и найти ошибки, но как быть с огромными, сложными страницами?
Лучше всего проверить страницу в сервисе валидации разметки. Его создал и поддерживает W3C — организация, которая занимается спецификациями HTML, CSS и других веб-технологий. Сервис проверит ваш HTML и составит отчёт по ошибкам в нем.
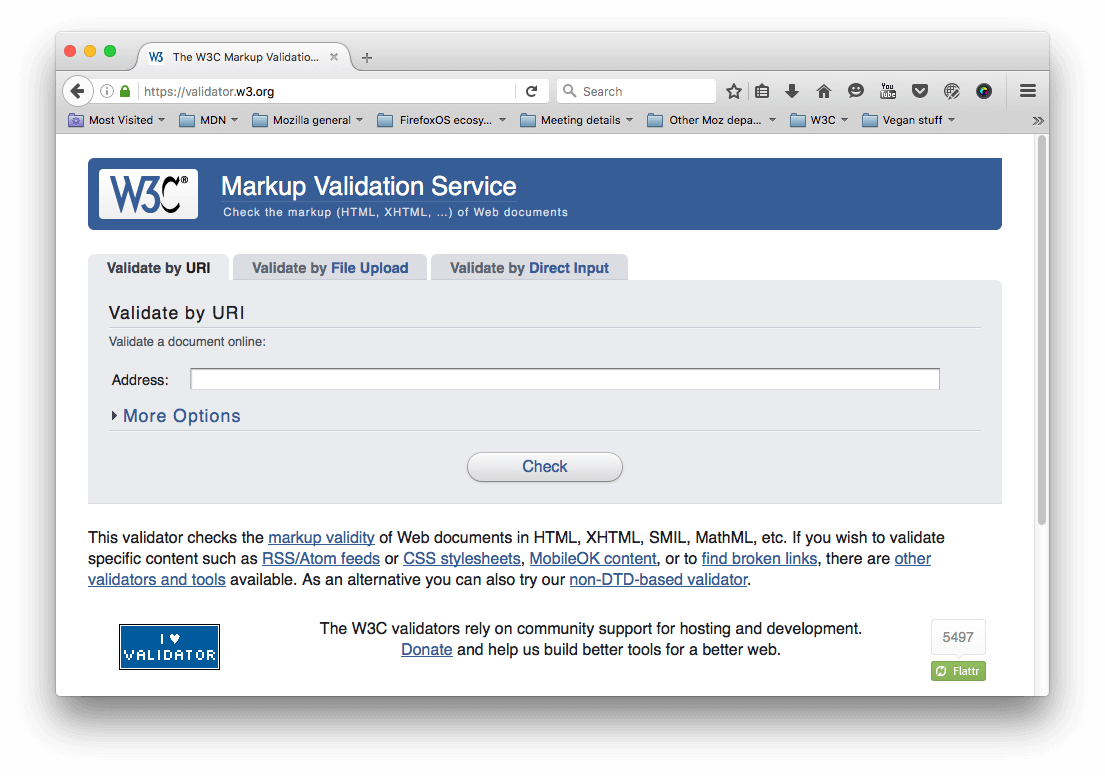
HTML можно проверить по адресу, загрузив файл или напрямую ввести код HTML.
Валидируем HTML-документ
Попробуем проверить документ-пример.
Вы увидите список ошибок и другую информацию.
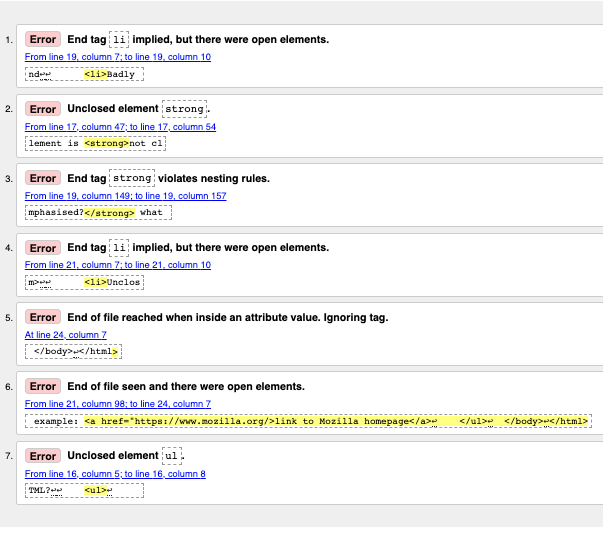
Работа с сообщениями об ошибках
Обычно сразу ясно, что значат сообщения, но иногда приходится постараться, чтобы понять, в чем дело. Сейчас мы пройдёмся по всем ошибкам и разберём, что они значат. Обратите внимание, что в сообщениях указаны строка и столбец кода, чтобы ошибки было проще искать.
Если некоторые ошибки кажутся вам странными, начните исправление с остальных и проверьте документ ещё раз. Иногда одна ошибка ломает большую часть документа.
Когда вы увидите эту надпись, в вашем документе больше нет ошибок:

Заключение
Теперь вы умеете отлаживать HTML. С новыми знаниями вам будет проще разобраться и в отладке более сложных языков — например, CSS и JavaScript. На этом мы заканчиваем вводный модуль курса HTML — время попробовать свои силы в упражнениях.
В этом модуле
Время на прочтение
Почти все разработчики так или иначе постоянно работают с api по http, клиентские разработчики работают с api backend своего сайта или приложения, а бэкендеры “дергают” бэкенды других сервисов, как внутренних, так и внешних. И мне кажется, одна из самых главных вещей в хорошем API это формат передачи ошибок. Ведь если это сделано плохо/неудобно, то разработчик, использующий это API, скорее всего не обработает ошибки, а клиенты будут пользоваться молчаливо ломающимся продуктом.
За 7 лет я как поддерживал множество legacy API, так и разрабатывал c нуля. И я поработал, наверное, с большинством стратегий по возвращению ошибок, но каждая из них создавала дискомфорт в той или иной мере. В последнее время я нащупал оптимальный вариант, о котором и хочу рассказать, но с начала расскажу о двух наиболее популярных вариантах.
HTTP статусы
Если почитать апологетов REST, то для кодов ошибок надо использовать HTTP статусы, а текст ошибки отдавать в теле или в специальном заголовке. Например:
Если у вас примитивная бизнес-логика или API из 5 url, то в принципе это нормальный подход. Однако как-только бизнес-логика станет сложнее, то начнется ряд проблем.
Http статусы предназначались для описания ошибок при передаче данных, а про логику вашего приложения никто не думал. Статусов явно не хватает для описания всего разнообразия ошибок в вашем проекте, да они и не были для этого предназначены. И тут начинается натягивание “совы на глобус”: все начинают спорить, какой статус ошибки дать в том или ином случае. Пример: Есть API для task manager. Какой статус надо вернуть в случае, если пользователь хочет взять задачу, а ее уже взял в работу другой пользователь? Ссылка на http статусы. И таких проблемных примеров можно придумать много.
REST скорее концепция, чем формат общения из чего следует неоднозначность использования статусов. Разработчики используют статусы как им заблагорассудится. Например, некоторые API при отсутствии сущности возвращают 404 и текст ошибки, а некоторые 200 и пустое тело.
Бэкенд разработчику в проекте непросто выбрать статус для ошибки, а клиентскому разработчику неочевидно какой статус предназначен для того или иного типа ошибок бизнес-логики. По-хорошему в проекте придется держать enum для того, чтобы описать какие ошибки относятся к тому или иному статусу.
Когда бизнес-логика приложения усложняется, начинают делать как-то так:
Из-за ограниченности http статусов разработчики начинают вводить “свои” коды ошибок для каждого статуса и передавать их в теле ответа. Другими словами, пользователю API приходится писать нечто подобное:
Из-за этого ветвление клиентского кода начинает стремительно расти: множество http статусов и множество кодов в самом сообщении. Для каждого ошибочного http статуса необходимо проверить наличие кодов ошибок в теле сообщения. От комбинаторного взрыва начинает конкретно пухнуть башка! А значит обработку ошибок скорее всего сведут к сообщению типа “Произошла ошибка” или к молчаливому некорректному поведению.
Многие системы мониторинга сервисов привязываются к http статусам, но это не помогает в мониторинге, если статусы используются для описания ошибок бизнес логики. Например, у нас резкий всплеск ошибок 429 на графике. Это началась DDOS атака, или кто-то из разработчиков выбрал неудачный статус?
Итог: Начать с таким подходом легко и просто и для простого API это вполне подойдет. Но если логика стала сложнее, то использование статусов для описания того, что не укладывается в заданные рамки протокола http приводит к неоднозначности использования и последующим костылям для работы с ошибками. Или что еще хуже к формализму, что ведет к неприятному пользовательскому опыту.
На все 200
Есть другой подход, даже более старый, чем REST, а именно: на все ошибки связанные с бизнес-логикой возвращать 200, а уже в теле ответа есть информация об ошибке. Например:
На самом деле формат зависит от вас или от выбранной библиотеки для реализации коммуникации, например JSON-API.
Звучит здорово, мы теперь отвязались от http статусов и можем спокойно ввести свои коды ошибок. У нас больше нет проблемы “впихнуть невпихуемое”. Выбор нового типа ошибки не вызывает споров, а сводится просто к введению нового числового номера (например, последовательно) или строковой константы. Например:
Клиентские разработчики просто основываясь на кодах ошибок могут создать классы/типы ошибок и притом не бояться, что сервер вернет один и тот же код для разных типов ошибок (из-за бедности http статусов).
Обработка ошибок становится менее ветвящейся, множество http статусов превратились в два: 200 и все остальные (ошибки транспорта).
В некоторых случаях, если есть библиотека десериализации данных, она может взять часть работы на себя. Писать SDK вокруг такого подхода проще нежели вокруг той или иной имплементации REST, ведь реализация зависит от того, как это видел автор. Кроме того, теперь никто не вызовет случайное срабатывание alert в мониторинге из-за того, что выбрал неудачный код ошибки.
Но неудобства тоже есть:
В некоторых случаях данный подход вырождается в RPC, то есть по сути вообще отказываются от использования url и шлют все на один url методом POST, а в теле сообщения передают все параметры. Мне кажется это не правильным, ведь url это прекрасный именованный namespace, зачем от этого отказываться, не понятно?! Кроме того, RPC создает проблемы:
Итог: Для сложной бизнес-логики с большим количеством типов ошибок такой подход лучше, чем расплывчатый REST, не зря в проектах c “разухабистой” бизнес-логикой часто именно такой подход и используют.
Смешанный
Возьмем лучшее от двух миров. Мы выберем один http статус, например, 400 или 422 для всех ошибок бизнес-логики, а в теле ответа будем указывать код ошибки или строковую константу. Например:
Тело ответа для удачного запроса у нас имеет произвольную структуру, а вот для ошибки есть четкая схема. Мы избавляемся от избыточности данных (поле ошибки/данных) благодаря использованию http статуса в сравнении со вторым вариантом. Клиентский код упрощается в плане обработки ошибки (в сравнении с первым вариантом). Также мы снижаем его вложенность за счет использования отдельного http статуса для ошибок бизнес логики (в сравнении со вторым вариантом).
Мы можем расширять объект ошибки для детализации проблемы, если хотим. С мониторингом все как во втором варианте, дописывать парсинг придется, но и риска “стрельбы” некорректными alert нету. Для документирования можем спокойно использовать Swagger и ApiDoc. При этом сохраняется удобство использования инструментов разработчика, таких как Chrome DevTools, Postman, Talend API.
Итог: Использую данный подход уже в нескольких проектах, где множество типов ошибок и все крайне довольны, как клиентские разработчики, так и бэкендеры. Внедрение новой ошибки не вызывает споров, проблем и противоречий. Данный подход объединяет преимущества первого и второго варианта, при этом код более читабельный и структурированный.
Самое главное какой бы формат ошибок вы бы не выбрали лучше обговорить его заранее и следовать ему. Если эту вещь пустить на “самотек”, то очень скоро обработка ошибок в проекте станет невыносимо сложной для всех.
P. S. Иногда ошибки любят передавать массивом
Но это актуально в основном в двух случаях:
Код состояния HTTP (англ. HTTP status code) — часть первой строки ответа сервера при запросах по протоколу HTTP.
Он представляет собой целое трёхразрядное десятичное число. Первая цифра указывает на класс состояния. За кодом ответа обычно следует отделённая пробелом поясняющая фраза на английском языке, которая разъясняет человеку причину именно такого ответа. Примеры:
Клиент может не знать все коды состояния, но он обязан отреагировать в соответствии с классом кода. В настоящее время выделено пять классов кодов состояния.
Веб-сервер Internet Information Services в своих файлах журналов, кроме стандартных кодов состояния, использует подкоды, записывая их через точку после основного. При этом в ответах от сервера данный подкод не размещается — он нужен администратору сервера, чтобы тот мог более точно определять источники проблем.
Ниже представлен обзорный список всех описанных в данной статье кодов ответа:
Диаграмма принятия веб-сервером решений на основе заголовков
Статистика по кодам ответа, сгенерированная анализатором логов Webalizer
В этот класс выделены коды, информирующие о процессе передачи. При работе через протокол версии 1.0 сообщения с такими кодами должны игнорироваться. В версии 1.1 клиент должен быть готов принять этот класс сообщений как обычный ответ, но серверу отправлять что-либо не нужно. Сами сообщения от сервера содержат только стартовую строку ответа и, если требуется, несколько специфичных для ответа полей заголовка. Прокси-серверы подобные сообщения должны отправлять дальше от сервера к клиенту.
Сообщения данного класса информируют о случаях успешного принятия и обработки запроса клиента.
В зависимости от статуса сервер может ещё передать заголовки и тело сообщения.
Коды этого класса сообщают клиенту, что для успешного выполнения операции необходимо сделать другой запрос, как правило, по другому URI. Из данного класса пять кодов 301, 302, 303, 305 и 307 относятся непосредственно к перенаправлениям. Адрес, по которому клиенту следует произвести запрос, сервер указывает в заголовке Location. При этом допускается использование фрагментов в целевом URI.
Поведение клиентов при различных перенаправлениях описано в таблице:
Класс кодов 4xx предназначен для указания ошибок со стороны клиента. При использовании всех методов, кроме HEAD, сервер должен вернуть в теле сообщения гипертекстовое пояснение для пользователя.
Сервер вернул ошибку 403 при попытке просмотра каталога «cgi-bin», доступ к которому был запрещён
Пример ошибки 502 Bad Gateway
Коды 5xx выделены под случаи необработанных исключений при выполнении операций на стороне сервера. Для всех ситуаций, кроме использования метода HEAD, сервер должен включать в тело сообщения объяснение, которое клиент отобразит пользователю.
Основные документы по протоколу HTTP (по убыванию даты публикации)
Документы по расширениям и обновлениям протокола HTTP (по убыванию даты публикации)