

«Цель этого курса — подготовить вас к вашему техническому будущему.»

Привет, Хабр. Помните офигенную статью «Вы и ваша работа» (+219, 2442 в закладки, 394k прочтений)?
Так вот у Хэмминга (да, да, самоконтролирующиеся и самокорректирующиеся коды Хэмминга) есть целая книга, написанная по мотивам его лекций. Мы ее переводим, ведь мужик дело говорит.
Это книга не просто про ИТ, это книга про стиль мышления невероятно крутых людей. « Это не просто заряд положительного мышления; в ней описаны условия, которые увеличивают шансы сделать великую работу.»
Мы уже перевели 26 (из 30) глав. И ведем работу над изданием «в бумаге».
Глава 12. Коды с коррекцией ошибок
В этой главе затронуты две темы: первая, очевидно, коды с коррекцией ошибок, а вторая — то, как иногда происходит процесс открытия. Как Вы все знаете, я официальный первооткрыватель кодов Хэмминга с коррекцией ошибок. Таким образом я, по-видимому, имею возможность описать, как они были найдены. Но вам необходимо остерегаться любых рассказов подобного типа. По правде говоря, в то время я уже очень интересовался процессом открытия, полагая во многих случаях, что метод открытия более важен, чем то, что открыто. Я знал достаточно, чтобы не думать о процессе во время исследований, так же, как спортсмены не думают о технике, когда выступают на соревнованиях, но отрабатывают её до автоматизма. Я также выработал привычку возвращаться назад после больших или малых открытий и пытаться отследить шаги, которые к ним привели. Но не обманывайтесь; в лучшем случае я могу описать сознательную часть и малую верхушку подсознательной части, но мы просто не знаем магии работы подсознания.
Я использовал релейный вычислитель Model 5 в Нью-Йорке, подготавливая его к отправке в Aberdeen Proving Grounds вместе с некоторым требуемым программным обеспечинием (главным образом математические программы). Если с помощью 2-из-5 блочных кодов обнаруживалась ошибка, машина, оставленная без присмотра, могла до трёх раз подряд повторять ошибочный цикл, прежде чем отбросить его и взять новую задачу, надеясь, что проблемное оборудование не будет задействовано в новом решении. Я был в то время, как говорится, старшим помощником младшего дворника, свободное машинное время я получал только на выходных — с 17-00 пятницы до 8-00 понедельника — это была уйма времени! Так я мог бы загрузить входную ленту с большим количеством задач и пообещать моим друзьям, вернувшись в Мюррей Хилл, Нью-Джерси, где находился исследовательский департамент, что я подготовлю ответы ко вторнику. Ну, в одни выходные, как только мы уехали вечером пятницы, машина полностью сломалась и у меня совершенно ничего не было к понедельнику. Я должен был принести извинения моим друзьям и пообещать им ответы к следующему вторнику. Увы! Та же ситуация случилась снова! Я был мягко говоря разгневан и воскликнул: «Если машина может определить, что ошибка существует, почему же она не определит где ошибка и не исправит её, просто изменив бит на противоположный?» (На самом деле, использованные выражения были чуть крепче!).
Заметим первым делом, что этот существенный сдвиг произошёл только потому, что я испытывал огромное эмоциональное напряжение в тот момент и это характерно для большинства великих открытий. Спокойная работа позволит вам улучшить и подробнее разработать идеи, но прорыв обычно приходит только после большого стресса и эмоциональной вовлечёности. Спокойный, холодный, не вовлечённый исследователь редко делает действительно большие новые шаги.
Вернёмся к рассказу. Я знал из предыдущих обсуждений, что конечно можно было бы соорудить три экземляра вычислителя, включая сравнивающие схемы, и использовать исправление ошибок методом голосования большинства. Но чего бы это стоило! Конечно, были и лучшие методы. Я также знал, как обсуждалось в предыдущей главе, о классной штуке с контролем чётности. Я разобрался в их строении очень внимательно.
С другой стороны, Пастер сказал: «Удача любит подготовленных». Как видите, я был подготовлен моей предыдущей работой. Я более чем хорошо знал кодирование «2-из-5», я понимал их фундаментально и работал и понимал общие последствия контроля чётности.
После некоторых размышлений я понял, что если я расположу биты любого символа сообщения в виде прямоугольника и запишу чётность каждого столбца и каждой строки, то две непрошедшие проверки чётности покажут мне координаты одной ошибки и это будет включать угловой добавленный бит чётности (который мог быть установлен соответственно, если я имел нечётные значения) Рис. 12. I. Избыточность, отношение того, что Вы используете, к минимально необходимому количеству, есть
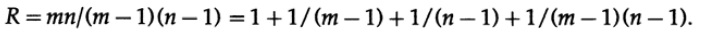
Любому, ко изучал матанализ, очевидно, что чем ближе прямоугольник к квадрату, тем меньше избыточность для сообщения того же размера. И, конечно, большие значения m и n были бы лучше, чем малые, но тогда риск двойной ошибки был бы велик с инженерной точки зрения. Заметим, что если две ошибки случаются, то Вы имеете:
если они не в одной строке или столбце, то просто две строки и два столбца содержат ошибки и мы не знаем, какая диагональная пара вызвала их;
если две ошибки случились в одной строке (или столбце), то у вас есть только один столбец (строка) и ни одной строки (столбца).
Перенесёмся сейчас на несколько недель позднее. Чтобы попасть в Нью-Йорк, я должен был добраться чуть раньше в Мюррей Хилл, Нью-Джерси, где я работал, и прокатиться на машине, доставляющей почту для компании. Ну да, поездка через северный Нью-Джерси ранним утром не очень живописна, поэтому я завёл привычку пересматривать свои достижения, так что перо вертелось в руках автоматически. В частности я крутил в голове прямоугольные коды. Внезапно, и я не знаю причин для этого, я обнаружил, что если я возьму треугольник и размещу биты контроля чётности на диагонали с тем, чтобы каждый бит проверял столбец и строку одновременно, то я получу более приемлемую избыточность, Рис 12. II.
Когда я возвратился к идее после нескольких дней отвлекающих событий (в конце концов, предполагалось, что я способствовал командным усилиям компании), я наконец решил, что хороший подход должен будет использовать синдром ошибки как двоичное число, указывающее место ошибки, с, конечно, всеми нулевыми битами в случае корректного результата (более лёгкий тест, чем для всех единиц на большинстве компьютеров). Заметьте, знакомство с двоичной системой, которая не была тогда распространена (1947-1948) неоднократно играло заметную роль в моих построениях. Это плата за знание большего, чем нужно сиюминутно!
Как Вы сконструируете этот частный случай кода, исправляющего ошибки? Легко! Запишите позиции в двоичном коде:
Теперь очевидно, что проверка чётности в правой половине синдрома должна включать все позиции, имеющие 1 в правом столбце; вторая цифра справа должна включить числа, имеющие 1 во втором столбце и т.д. Поэтому Вы имеете:

Таким образом, если ошибка происходит в некотором разряде, соответствующие проверки чётности (и только эти) провалятся и дадут 1 в синдроме, это составит в точности двоичное представление позиции ошибки. Это просто!
Чтобы увидеть код в действии, мы ограничимся 4 битами для сообщениями и 3 контрольными позициями. Эти числа удовлетворяют условию
которое очевидно является необходимым условием, а равенство — достаточным. Выберем для положения битов проверки (так, чтобы контроль чётности был проще ) контрольные разряды 1, 2 и 4. Позиции для сообщения — 3, 5, 6 7. Пусть сообщение будет
Мы
запишем сообщение в верхней строке,
закодируем следующую строку, вставим ошибку в позиции 6 на следующей строке и
на следующих трёх строках вычислим три проверки чётности.

Применим проверки чётности к полученному сообщению:
Если это кажется волшебством, подумайте о сообщении из всех 0, которое будет иметь контрольные позиции в 0, а после представьте изменение одного бита и Вы увидите как позиция ошибки перемещается, а следом двоичное число синдрома соответственно изменится и будет точно соответствовать положению ошибки. Затем обратите внимание, что сумма любых двух корректных сообщений является всё ещё корректным сообщением (проверки чётности являются аддитивными по модулю 2, следовательно корректные сообщения образуют аддитивную группу по модулю 2). Корректное сообщение даст все нули, следовательно сумма корректных сообщений плюс ошибка одном разряде даст положение ошибки независимо от отправляемого сообщения. Проверки чётности концентрируются на ошибке и игнорируют сообщение.
Теперь сразу очевидно, что любой обмен любыми двумя или больше из столбцов, однажды согласованных на каждом конце канала, не будет иметь никакого существенного эффекта; код будет эквивалентен. Точно так же перестановка 0 и 1 в любом столбце не даст существенно различных кодов. В частности, (так называемый) Код Хемминга является просто красивым переупорядочиванием, и на практике Вы могли бы проверять контрольные биты в конце сообщения, вместо того, чтобы рассеивать их посреди сообщения.
Как насчёт двойной ошибки? Если мы хотим поймать (но не исправить) двойную ошибку, мы просто добавляем единственную новую проверку чётности к целому сообщению, которое мы отправляем. Давайте посмотрим то, что тогда произойдёт на Вашем конце канала.

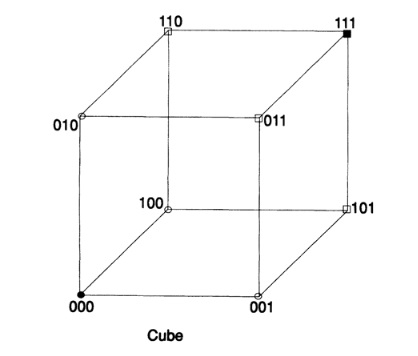
Из аналитической геометрии Вы усвоили значимость использования дополняющих алгебраических и геометрических представлений. Естественное представление строки битов должно использовать n-мерный куб, каждая строка которого является вершиной куба. Используя эту картинку и наконец заметив, что любая одна ошибка в сообщении перемещает сообщение вдоль одного ребра, две ошибки — вдоль двух ребер и т.д., я медленно понял, что я должен был действовать в пространстве $L_1$. Расстояние между элементами есть количество разрядов, в которых они различаются. Таким образом у нас есть метрика на пространстве и она удовлетворяет трём стандартным условиям для расстояния (см Главу 10 где определяется стандартное расстояние в L_1).

Таким образом я должен был отнестись серьёзно к тому, что я знал как абстракцию Пифагоровой функции расстояния.
Имея понятие расстояние, мы можем определить сферу как все точки (вершины, поскольку всё рассматривается в множестве вершин), на фиксированном расстоянии от центра. Например, в 3-мерном кубе, который может быть легко нарисован, Рис. 12. III, точки (0,0,1), (0,1,0), и (1,0,0) находятся на единичном расстоянии от (0,0,0), в то время как точки (1,1,0), (1,0,1), и (0,1,1) находятся на расстоянии 2 далее, и наконец точка (1,1,1) находится на расстоянии 3 от начала координат.
Перейдём теперь в пространство с n измерениями и нарисуем сферу единичного радиуса вокруг каждой точки и предположим, что сферы не пересекаются. Очевидно, что центры сфер есть элементы кода и только эти точки, тогда результатом получения любой единичной ошибки в сообщении будет «не-кодовая» точка и Вы сможете понять откуда эта ошибка пришла. Она будет внутри сферы вокруг точки кода, которую я вам послал, что эквивалентно сфере радиуса 1 вокруг точки кода, которую Вы получили. Следовательно, у нас есть код с коррекцией ошибок. Минимальное расстояние между кодовыми точками равно 3. Если мы используем не пересекающиеся сферы радиуса 2, тогда двойная ошибка может быть исправлена, потому что полученная точка будет ближе к оригинальной кодовой точке, чем к любой другой точке; минимальное расстояние для двойной коррекции равно 5. Следующая таблица показывает эквивалентность расстояния между кодовыми точками и «исправимостью» ошибок:

Таким образом построение кода с коррекцией ошибок в точности то же, что построение множества кодовых точек в n-мерном пространстве
которое имеет необходимое минимальное расстояние между легальными сообщениями, так как условия, приведенные выше, необходимы и достаточны. Также должно быть понятно, что мы можем обменять исправление ошибок на их обнаружение — откажитесь от исправления одной ошибки и Вы получите обнаружение ещё двух вместо.
Ранее я показал как разработать коды, удовлетворяющие условиям в случае, когда минимальное расстояние равно 1,2, 3 или 4. Коды с большими минимальными расстояниями не так легко описываются и мы не пойдем далее в этом направлении. Легко найти верхнюю оценку того, насколько велики могут быть кодовые расстояния. Очевидно, что количество точек в сфере радиуса k есть (C(n, k) — биномиальный коэффициент)
Следовательно, если мы разделим объём всего пространства, 2^n, на объём сферы, то частное будет оценкой сверху числа не пересекающихся сфер, т.е. точек кода, в соответствующем пространстве. Чтобы получить дополнительное обнаружение ошибок, мы как и прежде добавим полную проверку чётности, таким образом увеличив минимальное расстояние, которое было 2k+1, до 2k+2 (так как любые две точки на минимальном расстоянии будут иметь одинаковую чётность, увеличим минимальное расстояние на 1).
Давайте подведём итог, где мы теперь. Мы видим, что надлежащим построением кода мы можем создать систему из ненадёжных частей и получить гораздо более надёжную машину, и мы видим сколько мы должны заплатить за это оборудование, хотя мы не исследовали стоимость скорости вычисления, если мы создаём компьютер с таким уровнем коррекции ошибок. Но я ранее упомянул другую выгоду, а именно обслуживание при эксплуатации, и я хотел бы напомнить о нём снова. Чем более изощрённое оборудование, а мы очевидно движемся в этом направлении, тем более насущным является эксплуатационное обслуживание, коды с исправлением ошибок означают, что оборудование не только будет давать (возможно) верные ответы, но и может быть успешно обслужено низкоквалифицированным персоналом.
Использование кодов с обнаружением ошибок и кодов с коррекцией ошибок постоянно растёт в нашем обществе. Отправляя сообщения с космических кораблей, посланных к дальним планетам, мы часто располагаем 20 ваттами мощности или менее (возможно даже 5 ваттами) и используем коды, которые корректируют сотни ошибок в одном блоке сообщения — коррекция производится на Земле, конечно же. Когда Вы не готовы преодолеть шум как в вышеописанной ситуации или в случае «преднамеренного затора», то такие коды — единственный известный выход в этой ситуации.
Я хочу обратиться к другой части этой главы. Я аккуратно рассказал Вам многое из того, с чем я столкнулся на каждом этапе в обнаружении кодов с коррекцией ошибок, и что я сделал. Я сделал это по двум причинам. Во-первых, я хотел быть честным с Вами и показать Вам, как легко, следуя правилу Пастера «Удача улыбнётся подготовленным», преуспеть, просто готовя себя к успеху. Да, были элементы удачи в открытии; но в почти такой же ситуации было много других людей, и они не делали этого! Почему я? Удача, что и говорить, но также я подготовил себя к пониманию того, что происходило — больше, чем другие люди вокруг, просто реагировавшие на явления, когда они происходили, и не думающие глубоко относительно того, что было скрыто под поверхностью.
Я теперь бросаю вызов Вам. То, что я записал на нескольких страницах, было сделано в течение в общей сложности приблизительно трёх — шести месяцев, главным образом рабочих, в моменты обычного исполнения моих рабочих обязанностей в компании. ( Патентование отсрочило публикацию более чем на год). Может ли кто-либо сказать, что он, на моём месте, возможно, не сделал бы это? Да, Вы так же способны, как и я, были сделать это — если бы Вы были там, и Вы подготовились также!
Конечно, проживая свою жизнь, Вы не знаете к чему готовиться — Вы хотите совершить нечто значительное и не потратить всю Вашу жизнь, являясь «швейцаром науки» или чем Вы ещё занимаетесь. Конечно, удача играет видную роль. Но насколько я вижу, жизнь дарит Вам многие, многие возможности для того, чтобы сделать нечто большое (определите это как хотите сами) и подготовленный человек обычно достигает успеха один или несколько раз, а неподготовленный человек будет проваливаться почти каждый раз.
Вышеупомянутое мнение не основано на этом опыте, или просто на моих собственных событиях, это — результат изучения жизней многих великих учёных. Я хотел быть учёным, следовательно я изучил их, и я изучил открытия, произошедшие там, где я был, я задавал вопросы тем, кто сделал это. Это мнение также основано на здравом смысле. Вы растите в себе стиль выполнения больших свершений, и затем, когда возможность находится, Вы почти автоматически реагируете с максимальной крутизной в своих действиях. Вы обучили себя думать и действовать надлежащим способам.
Существует один противный тезис, который надо упомянуть, однако, что быть великим в эпоху — это не то, что нужно в последующие годы уточнить. Таким образом Вы, готовя себя к будущим великим свершениям (а их возможность более распространена и их легче достигнуть, чем Вы думаете, так как не часто распознают большие свершения, когда это происходит под носом), необходимо думать о природе будущего, в котором Вы будете жить. Прошлое является частичным руководством, и единственное, что Вы имеете помимо истории, есть постоянное использование Вашего собственного воображения. Снова, случайный перебор случайных решений не приведёт Вас куда либо так далеко, как решения, принятые с Вашим собственным видением того, каким Ваше будущее должно быть.
Я и рассказал и показал Вам, как быть великим; теперь у Вас нет оправдания того, что Вы не делаете этого!
Кстати, мы еще запустили перевод еще одной крутейшей книги — «The Dream Machine: История компьютерной революции»)
Содержание книги и переведенные главы
Корректирующие коды. Начало новой теории кодирования
Время на прочтение

Проблемы информационной безопасности требуют изучения и решения ряда теоретических и практических задач при информационном взаимодействии абонентов систем. В нашей доктрине информационной безопасности формулируется триединая задача обеспечения целостности, конфиденциальности и доступности информации. Представляемые здесь статьи посвящаются рассмотрению конкретных вопросов ее решения в рамках разных государственных систем и подсистем. Ранее автором были рассмотрены в 5 статьях вопросы обеспечения конфиденциальности сообщений средствами государственных стандартов. Общая концепция системы кодирования также приводилась мной ранее.
Введение
По основному своему образованию я не математик, но в связи с читаемыми мной дисциплинами в ВУЗе пришлось в ней дотошно разбираться. Долго и упорно читал классические учебники ведущих наших Университетов, пятитомную математическую энциклопедию, множество тонких популярных брошюр по отдельным вопросам, но удовлетворения не возникало. Не возникало и глубокое понимание прочитанного.
Вся математическая классика ориентирована, как правило, на бесконечный теоретический случай, а специальные дисциплины опираются на случай конечных конструкций и математических структур. Отличие подходов колоссальное, отсутствие или недостаток хороших полных примеров — пожалуй главный минус и недостаток вузовских учебников. Очень редко существует задачник с решениями для начинающих (для первокурсников), а те, что имеются, грешат пропусками в объяснениях. В общем я полюбил букинистические магазины технической книги, благодаря чему пополнилась библиотека и в определенной мере багаж знаний. Читать довелось много, очень много, но «не заходило».
Этот путь привел меня к вопросу, а что я уже могу самостоятельно делать без книжных «костылей», имея перед собой только чистый лист бумаги и карандаш с ластиком? Оказалось совсем немного и не совсем то, что было нужно. Пройден был сложный путь бессистемного самообразования. Вопрос был такой. Могу ли я построить и объяснить, прежде всего себе, работу кода, обнаруживающего и исправляющего ошибки, например, код Хемминга, (7, 4)-код?
Известно, что код Хемминга широко используется во многих прикладных программах в области хранения и обмена данными, особенно в RAID; кроме того, в памяти типа ECC и позволяет «на лету» исправлять однократные и обнаруживать двукратные ошибки.
Информационная безопасность. Коды, шифры, стегосообщения
Информационное взаимодействие путем обмена сообщениями его участников должно обеспечиваться защитой на разных уровнях и разнообразными средствами как аппаратными так и программными. Эти средства разрабатываются, проектируются и создаются в рамках определенных теорий (см. рис. А) и технологий, принятых международными договоренностями об OSI/ISO моделях.
Защита информации в информационных телекоммуникационных системах (ИТКС) становится практически основной проблемой при решении задач управления, как в масштабе отдельной личности – пользователя, так и для фирм, объединений, ведомств и государства в целом. Из всех аспектов защиты ИТКС в этой статье будем рассматривать защиту информации при ее добывании, обработке, хранении и передаче в системах связи.
Уточняя далее предметную область, остановимся на двух возможных направлениях, в которых рассматриваются два различных подхода к защите, представлению и использованию информации: синтаксическом и семантическом. На рисунке используются сокращения: кодек–кодер-декодер; шидеш – шифратор-дешифратор; скриз – скрыватель – извлекатель.
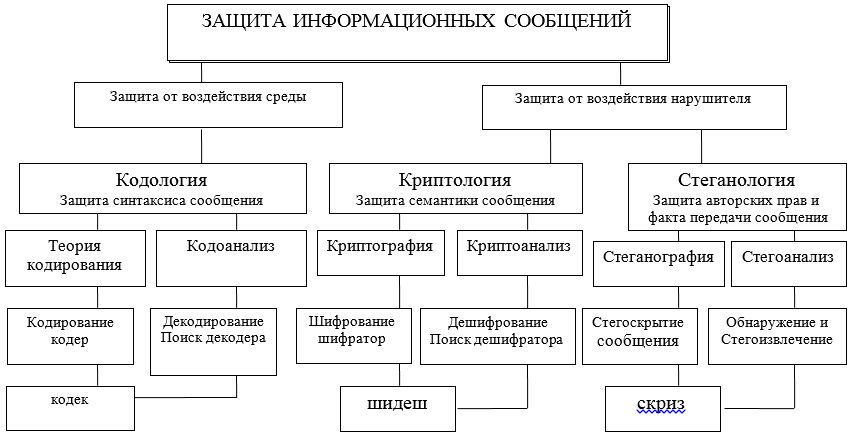
Рисунок А – Схема основных направлений и взаимосвязи теорий, направленных на решение задач защиты информационного взаимодействия
Синтаксические особенности представления сообщений позволяют контролировать и обеспечивать правильность и точность (безошибочность, целостность) представления при хранении, обработке и особенно при передаче информации по каналам связи. Здесь главные задачи защиты решаются методами кодологии, ее большой части — теории корректирующих кодов.
Семантическая (смысловая) безопасность сообщений обеспечивается методами криптологии, которая средствами криптографии позволяет защитить от овладения содержанием информации потенциальным нарушителем. Нарушитель при этом может скопировать, похитить, изменить или подменить, или даже уничтожить сообщение и его носитель, но он не сможет получить сведений о содержании и смысле передаваемого сообщения. Содержание информации в сообщении останется для нарушителя недоступным. Таким образом, предметом дальнейшего рассмотрения будет синтаксическая и семантическая защита информации в ИТКС. В этой статье ограничимся рассмотрением только синтаксического подхода в простой, но весьма важной его реализации корректирующим кодом.
Сразу проведу разграничительную линию в решении задач информационной безопасности:
теория кодологии призвана защищать информацию (сообщения) от ошибок (защита и анализ синтаксиса сообщений) канала и среды, обнаруживать и исправлять ошибки;
теория криптологии призвана защищать информацию от несанкционированного доступа к ее семантике нарушителя (защита семантики, смысла сообщений);
теория стеганологии призвана защищать факт информационного обмена сообщениями, а также обеспечивать защиту авторского права, персональных данных (защита врачебной тайны).
В общем «поехали». По определению, а их довольно много, понять что есть код очень даже не просто. Авторы пишут, что код — это алгоритм, отображение и ещё что-то. О классификации кодов я не буду здесь писать, скажу только, что (7, 4)-код блоковый.
В какой-то момент до меня дошло, что код — это кодовые специальные слова, конечное их множество, которыми заменяют специальными алгоритмами исходный текст сообщения на передающей стороне канала связи и которые отправляются по каналу получателю. Замену осуществляет устройство-кодер, а на приемной стороне эти слова распознает устройство-декодер.
Алфавит и слова — это уже язык, известно, что естественные человеческие языки избыточны, но что это означает, где обитает избыточность языка трудно сказать, избыточность не очень хорошо организована, хаотична. При кодировании, хранении информации избыточность стремятся уменьшить, пример, архиваторы, код Морзе и др.
Ричард Хемминг, наверное, раньше других понял, что если избыточность не устранять, а разумно организовать, то ее можно использовать в системах связи для обнаружения ошибок и автоматического их исправления в кодовых словах передаваемого текста. Он понял, что все 128 семиразрядных двоичных слов могут использоваться для обнаружения ошибок в кодовых словах, которые образуют код — подмножество из 16 семиразрядных двоичных слов. Это была гениальная догадка.
До изобретения Хемминга ошибки приемной стороной тоже обнаруживались, когда декодированный текст не читался или получалось не совсем то, что нужно. При этом посылался запрос отправителю сообщения повторить блоки определенных слов, что, конечно, было весьма неудобно и тормозило сеансы связи. Это было большой не решаемой десятилетиями проблемой.
Построение (7, 4)-кода Хемминга
Вернемся к Хеммингу. Слова (7, 4)-кода образованы из 7 разрядов С j =
Линейные функциональные зависимости (правила (*)) вычислений значений символов
Исправление ошибки стало очень простой операцией — в ошибочном разряде определялся символ (ноль или единица) и заменялся другим противоположным 0 на 1 или 1 на 0.
Сколько же различных слов образуют код? Ответ на этот вопрос для (7, 4)-кода получается очень просто. Раз имеется лишь 4 информационных разряда, а их разнообразие при заполнении символами имеет
Информационные части этих 16 слов получают нумерованный вид №
(
0=0000; 4= 0100; 8=1000; 12=1100;
1=0001; 5= 0101; 9=1001; 13=1101;
2=0010; 6= 0110; 10=1010; 14=1110;
3=0011; 7= 0111; 11=1011; 15=1111.
Каждому из этих 4-разрядных слов необходимо вычислить и добавить справа по 3 проверочных разряда, которые вычисляются по правилам (*). Например, для информационного слова №6 равного 0110 имеем
Шестое кодовое слово при этом приобретает вид:
Таким же образом необходимо вычислить проверочные символы для всех 16-и кодовых слов. Подготовим для слов кода 16-строчную таблицу К и последовательно будем заполнять ее клетки (читателю рекомендую проделать это с карандашом в руках).
Таблица К – кодовые слова Сj, j = 0
15, (7, 4) – кода Хемминга
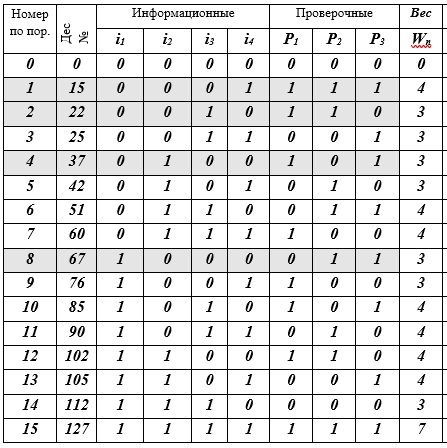
Описание таблицы: 16 строк — кодовые слова; 10 колонок: порядковый номер, десятичное представление кодового слова, 4 информационных символа, 3 проверочных символа, W-вес кодового слова равен числу ненулевых разрядов (≠ 0). Заливкой выделены 4 кодовых слова-строки — это базис векторного подпространства. Собственно, на этом все — код построен.
Таким образом, в таблице получены все слова (7, 4) — кода Хемминга. Как видите это было не очень сложно. Далее речь пойдет о том, какие идеи привели Хемминга к такому построению кода. Мы все знакомы с кодом Морзе, с флотским семафорным алфавитом и др. системами построенными на разных эвристических принципах, но здесь в (7, 4)-коде используются впервые строгие математические принципы и методы. Рассказ будет как раз о них.
Математические основы кода. Высшая алгебра
Подошло время рассказать какая Р. Хеммингу пришла идея открытия такого кода. Он не питал особых иллюзий о своем таланте и скромно формулировал перед собой задачу: создать код, который бы обнаруживал и исправлял в каждом слове одну ошибку (на деле обнаруживать удалось даже две ошибки, но исправлялась лишь одна из них). При качественных каналах даже одна ошибка — редкое событие. Поэтому замысел Хемминга все-таки в масштабах системы связи был грандиозным. В теории кодирования после его публикации произошла революция.
Это был 1950 год. Я привожу здесь свое простое (надеюсь доступное для понимания) описание, которого не встречал у других авторов, но как оказалось, все не так просто. Потребовались знания из многочисленных областей математики и время, чтобы все глубоко осознать и самому понять, почему это так сделано. Только после этого я смог оценить ту красивую и достаточно простую идею, которая реализована в этом корректирующем коде. Время я в основном, потратил на разбирательство с техникой вычислений и теоретическим обоснованием всех действий, о которых здесь пишу.
Создатели кодов, долго не могли додуматься до кода, обнаруживающего и исправляющего две ошибки. Идеи, использованные Хеммингом, там не срабатывали. Пришлось искать, и нашлись новые идеи. Очень интересно! Захватывает. Для поиска новых идей потребовалось около 10 лет и только после этого произошел прорыв. Коды, обнаруживающие произвольное число ошибок, были получены сравнительно быстро.
Векторные пространства, поля и группы. Полученный (7, 4)-код (Таблица К) представляет множество кодовых слов, являющихся элементами векторного подпространства (порядка 16, с размерностью 4), т.е. частью векторного пространства размерности 7 с порядком
Во-первых, они являются подпространством со всеми вытекающими отсюда свойствами и особенностями, во-вторых, кодовые слова являются подгруппой большой группы порядка 128, даже более того, аддитивной подгруппой конечного расширенного поля Галуа GF(
) степени расширения n = 7 и характеристики 2. Эта большая подгруппа раскладывается в смежные классы по меньшей подгруппе, что хорошо иллюстрируется следующей таблицей Г. Таблица разделена на две части: верхняя и нижняя, но читать следует как одну длинную. Каждый смежный класс (строка таблицы) — элемент факторгруппы по эквивалентности составляющих.
Таблица Г – Разложение аддитивной группы поля Галуа GF () в смежные классы (строки таблицы Г) по подгруппе 16 порядка.
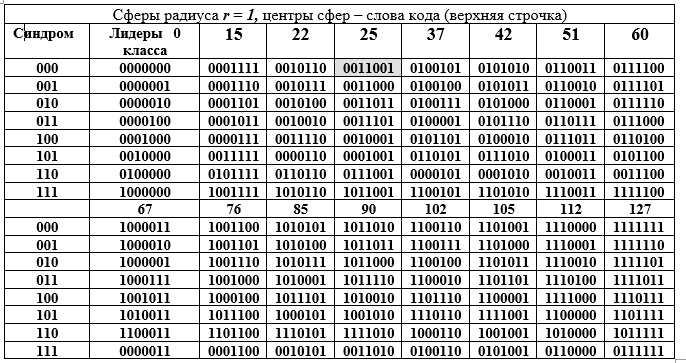
Столбцы таблицы – это сферы радиуса 1. Левый столбец (повторяется) – синдром слова (7, 4)-кода Хемминга, следующий столбец — лидеры смежного класса. Раскроем двоичное представление одного из элементов (25-го выделен заливкой) факторгруппы и его десятичное представление:
Техника получение строк таблицы Г. Элемент из столбца лидеров класса суммируется с каждым элементом из заголовка столбца таблицы Г (суммирование выполняется для строки лидера в двоичном виде по mod2). Поскольку все лидеры классов имеют вес W=1, то все суммы отличаются от слова в заголовке столбца только в одной позиции (одной и той же для всей строки, но разных для столбца). Таблица Г имеет замечательную геометрическую интерпретацию. Все 16 кодовых слов представляются центрами сфер в 7-мерном векторном пространстве. Все слова в столбце от верхнего слова отличаются в одной позиции, т. е. лежат на поверхности сферы с радиусом r =1.
В этой интерпретации скрывается идея обнаружения одной ошибки в любом кодовом слове. Работа идет со сферами. Первое условие обнаружения ошибки — сферы радиуса 1 не должны касаться или пересекаться. Это означает, что центры сфер удалены друг от друга на расстояние 3 или более. При этом сферы не только не пересекаются, но и не касаются одна другой. Это требование для однозначности решения: какой сфере отнести полученное на приемной стороне декодером ошибочное (не кодовое одно из 128 -16 = 112) слово.
Второе — все множество 7-разрядных двоичных слов из 128 слов равномерно распределено по 16 сферам. Декодер может получить слово лишь из этого множества 128-ми известных слов с ошибкой или без нее. Третье — приемная сторона может получить слово без ошибки или с искажением, но всегда принадлежащее одной из 16-и сфер, которая легко определяется декодером. В последней ситуации принимается решение о том, что послано было кодовое слово — центр определенной декодером сферы, который нашел позицию (пересечение строки и столбца) слова в таблице Г, т. е номера столбца и строки.
Здесь возникает требование к словам кода и к коду в целом: расстояние между любыми двумя кодовыми словами должно быть не менее трех, т. е. разность для пары кодовых слов, например, Сi = 85=
=1010101; Сj = 25=
= 0011001 должна быть не менее 3; 85 — 25 = 1010101 — 0011001 =1001100 = 76, вес слова-разности W(76) = 3. (табл. Д заменяет вычисления разностей и сумм). Здесь под расстоянием между двоичными словами-векторами понимается количество не совпадающих позиций в двух словах. Это расстояние Хемминга, которое стало повсеместно использоваться в теории, и на практике, так как удовлетворяет всем аксиомам расстояния.
Замечание. (7, 4)-код не только линейный блоковый двоичный, но он еще и групповой, т. е. слова кода образуют алгебраическую группу по сложению. Это означает, что любые два кодовых слова при суммировании снова дают одно из кодовых слов. Только это не обычная операция суммирования, выполняется сложение по модулю два.
Таблица Д — Сумма элементов группы (кодовых слов), используемой для построения кода Хемминга
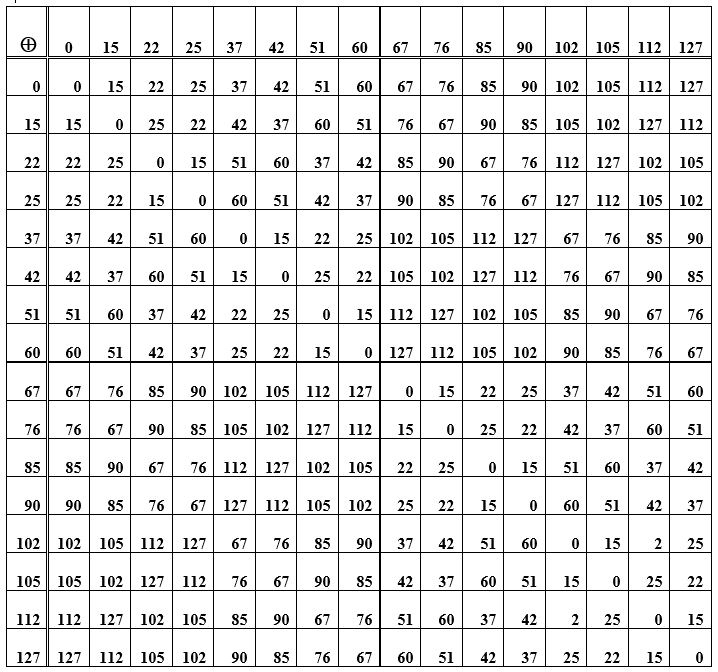
Сама операция суммирования слов ассоциативна, и для каждого элемента в множестве кодовых слов имеется противоположный ему, т. е. суммирование исходного слова с противоположным дает нулевое значение. Это нулевое кодовое слово является нейтральным элементом в группе. В таблице Д- это главная диагональ из нулей. Остальные клетки (пересечения строка/столбец) — это номера-десятичные представления кодовых слов, полученные суммированием элементов из строки и столбца. При перестановке слов местами (при суммировании) результат остается прежним, более того, вычитание и сложение слов имеют одинаковый результат. Дальше рассматривается система кодирования/декодирования, реализующая синдромный принцип.
Применение кода. Кодер
Кодер размещается на передающей стороне канала и им пользуется отправитель сообщения. Отправитель сообщения (автор) формирует сообщение в алфавите естественного языка и представляет его в цифровом виде. ( Имя символа в ASCII-соде и в двоичном виде).
Тексты удобно формировать в файлах для ПК с использованием стандартной клавиатуры (ASCII — кодов). Каждому символу (букве алфавита) соответствует в этой кодировке октет бит (восемь разрядов). Для (7, 4)- кода Хемминга, в словах которого только 4 информационных символа, при кодировании символа клавиатуры на букву требуется два кодовых слова, т.е. октет буквы разбивается на два информационных слова естественного языка (ЕЯ) вида
Пример 1. Необходимо передать слово «цифра» в ЕЯ. Входим в таблицу ASCII-кодов, буквам соответствуют: ц –11110110, и –11101000, ф – 11110100, р – 11110000, а – 11100000 октеты. Или иначе в ASCII — кодах слово «цифра» = 1111 0110 1110 1000 1111 0100 1111 0000 1110 0000
с разбивкой на тетрады (по 4 разряда). Таким образом, кодирование слова «цифра» ЕЯ требует 10 кодовых слов (7, 4)-кода Хемминга. Тетрады представляют информационные разряды слов сообщения. Эти информационные слова (тетрады) преобразуются в слова кода (по 7 разрядов) перед отправкой в канал сети связи. Выполняется это путем векторно-матричного умножения: информационного слова на порождающую матрицу. Плата за удобства получается весьма дорого и длинно, но все работает автоматически и главное — сообщение защищается от ошибок.
Порождающая матрица (7, 4)-кода Хемминга или генератор слов кода получается выписыванием базисных векторов кода и объединением их в матрицу. Это следует из теоремы линейной алгебры: любой вектор пространства (подпространства) является линейной комбинацией базисных векторов, т.е. линейно независимых в этом пространстве. Это как раз и требуется — порождать любые векторы (7-разрядные кодовые слова) из информационных 4-разрядных.
Порождающая матрица (7, 4, 3)-кода Хемминга или генератор слов кода имеет вид:
Справа указаны десятичные представления кодовых слов Базиса подпространства и их порядковые номера в таблице К
№ i строки матрицы — это слова кода, являющиеся базисом векторного подпространства.
Информационные слова сообщения имеют вид:
Это половины символа (ц). Для (7, 4)-кода, определенного ранее, требуется найти кодовые слова, соответствующее информационному слову-сообщению (ц) из 8-и символов в виде:
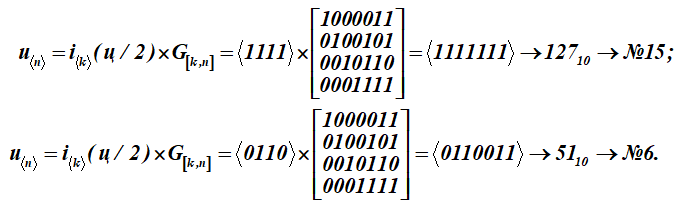
Получили два кодовых слова с порядковыми номерами 15 и 6.
Покажем детальное формирование нижнего результата №6 – кодового слова (умножение строки информационного слова на столбцы порождающей матрицы); суммирование по (mod2)
В результате перемножения получили 15 и 6 слова таблицы К кода.
Применение кода. Декодер
Декодер размещается на приемной стороне канала там, где находится получатель сообщения. Назначение декодера состоит в предоставлении получателю переданного сообщения в том виде, в котором оно существовало у отправителя в момент отправления, т.е. получатель может воспользоваться текстом и использовать сведения из него для своей дальнейшей работы.
Рассматриваемый код является систематическим, т. е. символы информационного слова размещаются подряд в старших разрядах кодового слова. Восстановление информационных слов выполняется простым отбрасыванием младших (проверочных) разрядов, число которых известно. Далее используется таблица ASCII-кодов в обратном порядке: входом являются информационные двоичные последовательности, а выходом – буквы алфавита естественного языка. Итак, (7, 4)-код систематический, групповой, линейный, блочный, двоичный.


Видим, что произведение порождающей матрицы на проверочную в результате дает нулевую матрицу.

В результате вычисленный синдром имеет нулевое значение, что подтверждает отсутствие ошибки в словах кода.
Пример 3. Обнаружение одной ошибки в слове, полученном на приемном конце канала (таблица К).
А) Пусть требуется передать 7 – е кодовое слово, т.е.
Установление факта искажения кодового слова выполняется умножением полученного искаженного слова на проверочную матрицу кода. Результатом такого умножения будет вектор, называемый синдромом кодового слова.
Выполним такое умножение для наших исходных (7-го вектора с ошибкой) данных.

Вот собственно и все, именно так устроен и работает классический (7, 4)-код Хемминга.
Здесь не рассматриваются многочисленные модификации и модернизации этого кода, так как важны не они, а те идеи и их реализации, которые в корне изменили теорию кодирования, и как следствие, системы связи, обмена информацией, автоматизированные системы управления.
Заключение
В работе рассмотрены основные положения и задачи информационной безопасности, названы теории, призванные решать эти задачи.
Задача защиты информационного взаимодействия субъектов и объектов от ошибок среды и от воздействий нарушителя относится к кодологии.
Рассмотрен в деталях (7, 4)-код Хемминга, положивший начало нового направлению в теории кодирования — синтеза корректирующих кодов.
Показано применение строгих математических методов, используемых при синтезе кода.
Приведены примеры иллюстрирующие работоспособность кода.
Литература
Питерсон У., Уэлдон Э. Коды, исправляющие ошибки: Пер. с англ. М.: Мир, 1976, 594 c.
Блейхут Р. Теория и практика кодов, контролирующих ошибки. Пер.с англ. М.: Мир, 1986, 576 с.
Пример
. Предположим, в канале связи под действием
помех произошло искажение и вместо
0100101 было принято 01001
1.
Решение:
Для обнаружения ошибки производят уже
знакомые нам проверки на четность.
Первая
проверка:
сумма П1+П3+П5+П7
= 0+0+1+1 четна.
В младший разряд номера ошибочной
позиции запишем 0.
Вторая
проверка:
сумма П2+П3+П6+П7
= 1+0+1+1 нечетна.
Во второй разряд номера ошибочной
позиции запишем 1
Третья
проверка:
сумма П4+П5+П6+П7
= 0+1+1+1 нечетна.
В третий разряд номера ошибочной позиции
запишем 1. Номер ошибочной позиции 110=
6. Следовательно,
символ шестой позиции следует изменить
на обратный, и получим правильную кодовую
комбинацию.
Код, исправляющий
одиночную и обнаруживающий двойную
ошибки
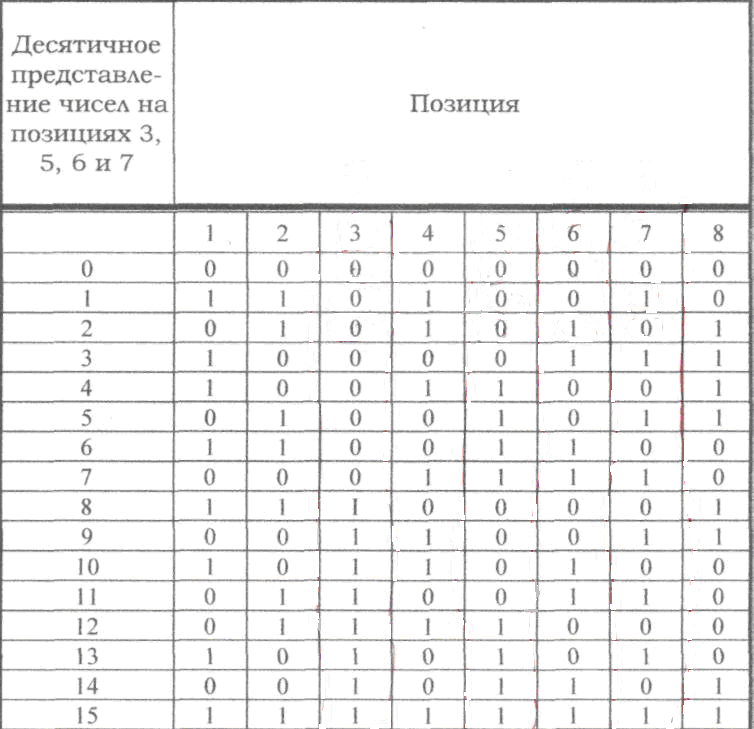
Если по изложенным
выше правилам строить корректирующий
код с обнаружением и исправлением
одиночной ошибки для равномерного
двоичного кода, то первые 16 кодовых
комбинаций будут иметь вид, показанный
в таблице. Такой код может быть использован
для построения кода с исправлением
одиночной ошибки и обнаружением двойной.
Для
этого, кроме указанных выше проверок
по контрольным позициям, следует провести
еще одну проверку на четность для всей
строки в целом. Чтобы осуществить такую
проверку, следует к каждой строке кода
добавить контрольные символы, записанные
в дополнительной колонке (таблица,
колонка 8). Тогда в случае одной ошибки
проверки по позициям укажут номер
ошибочной позиции, а проверка на четность
– на наличие ошибки. Если проверки позиций
укажут на наличие ошибки, а проверка на
четность не фиксирует ее, значит в
кодовой комбинации две ошибки.
1 Двоичные циклические коды
Вышеприведенная
процедура построения линейного кода
матричным методом имеет ряд недостатков.
Она неоднозначна (МДР можно задать
различным образом) и неудобна
в реализации в виде технических устройств.
Этих недостатков лишены
линейные корректирующие коды, принадлежащие
к классу циклических.
Циклическими
называют
линейные (n,k)-коды,
обладающие
следующим свойством:
для любого кодового слова:
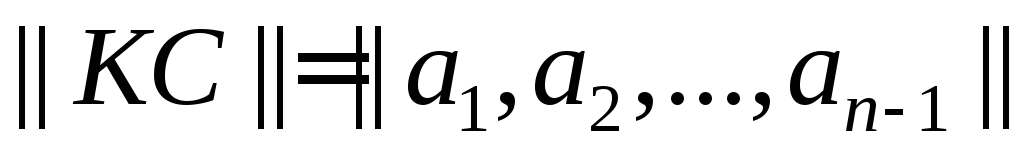
существует другое
кодовое слово:
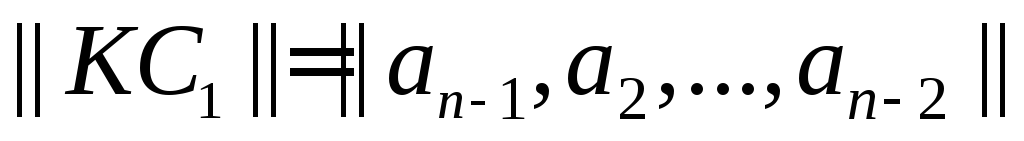
Для
описания циклических кодов используют
полиномы с фиктивной переменной
X.
Его
можно описать полиномом
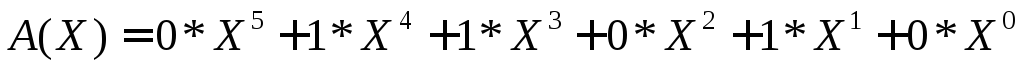
Таким
образом, разряды кодового слова в
описывающем его полиноме используются
в качестве коэффициентов при степенях
фиктивной переменной
X.
Наибольшая
степень фиктивной переменной X
в
слагаемом с ненулевым
коэффициентом называется степенью
полинома. В вышеприведенном примере
получился полином 4-й степени.
Теперь
действия над кодовыми словами сводятся
к действиям над полиномами.
Вместо алгебры матриц здесь используется
алгебра полиномов.
Рассмотрим
алгебраические действия над полиномами,
используемые в теории
циклических кодов. Суммирование
полиномов разберем на примере
С(Х)=А(Х)+В(Х).
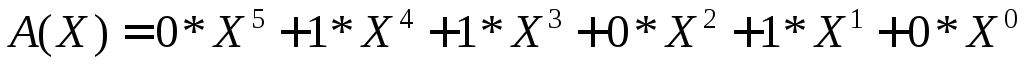

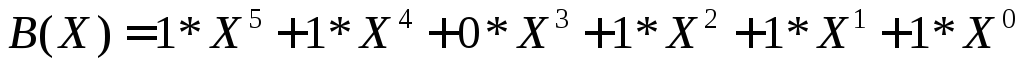
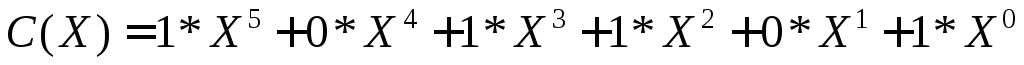
Таким
образом, при суммировании коэффициентов
при X
в одинаковой степени
результат берется по модулю 2. При таком
правиле вычитание эквивалентно
суммированию.
Умножение
выполняется как обычно, но с использованием
суммирования
по модулю 2.
Рассмотрим
умножение на примере умножения полинома
(X3+X1+X0)
Х4+
X3+
X2+0*X1+X0
Операция
– обратная умножению -деление. Деление
полиномов выполняется как обычно, за
исключением того, что вычитание
выполняется по модулю 2. Вспомним, что
вычитание по модулю 2 эквивалентно
сложению по модулю 2
Пример
деления полинома X6+X4+X3
на полином
X3+X2+1
X5
+X4
+ 0*X3+
X2
Проверим это на
примере.
Пусть требуется
выполнить циклический сдвиг влево на
одну позицию
В результате должен
получиться полином
В
основе циклического кода лежит образующий
полином r-го
порядка
(напомним, что r-
число дополнительных разрядов). Будем
обозначать
его gr(X).
Образование
кодовых слов (кодирование) КС
выполняется
путем умножения
информационного полинома с коэффициентами,
являющимися информационной
последовательностью
И(Х)
порядка
i<k
на
образующий полином gr(X)
Принятое кодовое
слово может отличаться от переданного
искаженными разрядами в результате
воздействия помех.
где
ВО(Х)
– полином
вектора ошибки, а суммирование, как
обычно, ведется
по модулю 2.
Декодирование,
как и раньше начинается с нахождения
опознавателя,
в данном случае в виде полинома ОП(Х).
Этот
полином вычисляется как
остаток от деления полинома принятого
кодового слова ПКС(Х)
на
образующий
полином g(Х):
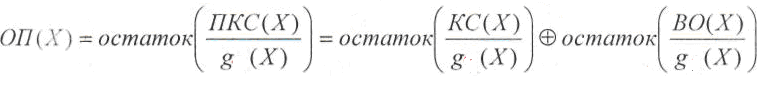
Первое
слагаемое остатка не имеет, т.к. кодовое
слово было образовано путем умножения
полинома информационной последовательности
на
образующий полином. Следовательно, и в
данном случае опознаватель
полностью зависит от вектора ошибки.
Образующий
полином выбирается таким, чтобы при
данном r
как
можно
большее число отношений ВО(Х)/g(Х)
давало
различные остатки.
Такому
требованию отвечают так называемые
неприводимые
полиномы,
которые
не делятся без остатка ни на один полином
степени r
и ниже, а
делятся только сами на себя и на 1.
Приведенная
здесь процедура образования кодового
слова неудобна тем,
что такой код получается несистематическим,
т.е. таким, в кодовых словах
которого нельзя выделить информационные
и дополнительные разряды.
Этот недостаток
был устранен следующим образом.
Способ
кодирования, приводящий к получению
систематического линейного циклического
кода, состоит в приписывании к
информационной
последовательности И
дополнительных разрядов ДР.
Эти
дополнительные разряды предлагается
находить по следующей формуле:
Порядок
полинома ДР(Х)
гарантировано
меньше r
(поскольку
это остаток).
Приписывание
дополнительных разрядов к информационной
последовательности,
используя алгебру полиномов, можно
описать формулой:
Одним
из свойств циклических линейных кодов
является то, что результат
деления любого разрешенного кодового
слова КС
на
образующий полином также, является
разрешенным кодовым словом.
Покажем,
что получаемые по вышеприведенному
алгоритму кодовые
слова являются кодовыми словами
циклического линейного кода. Для
этого нужно убедиться в том, что
произвольное разрешенное кодовое
слово делится на образующий полином
g(X)
без остатка:
где
d(Х)
– целая
часть результата деления.
Подставим полученную
сумму на место первого слагаемого:
–
целая часть деления. Остатка нет. Это
означает,
что описанный выше способ кодирования
соответствует циклическому
коду.
Код Хэ́мминга — самоконтролирующийся и самокорректирующийся код. Построен применительно к двоичной системе счисления.
Назван в честь американского математика Хэмминга Ричарда Уэсли, предложившего код.