

Код Хэ́мминга
— самоконтролирующийся и самокорректирующийся код
. Построен применительно к двоичной системе счисления
.
Назван в честь американского математика Хэмминга Ричарда Уэсли
, предложившего код.
Код Хэмминга
является разновидностью линейных кодов
и позволяет не только обнаруживать, но
и исправлять ошибки. В коде Хэмминга
вводится понятие кодового расстояния–
это степень различия кодовых комбинаций
. Кодовое расстояние для двух любых
кодовых комбинаций определяется числом
несовпадающих в них разрядов. Наименьшее
кодовое расстояние называется минимальным
кодовым расстоянием

(
расстояние Хэмминга ).
К кодам Хэмминга
обычно относятся коды с
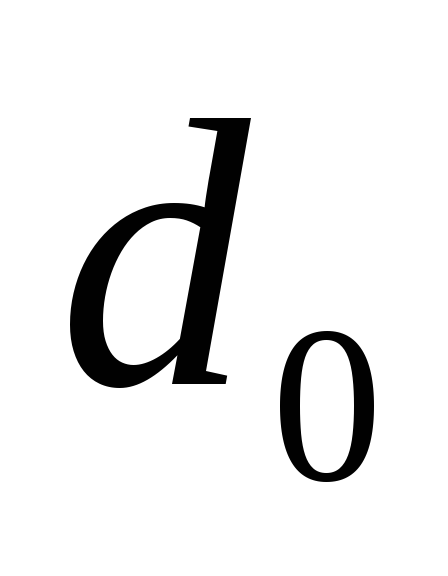
=3,
исправляющие все одиночные ошибки и
коды с 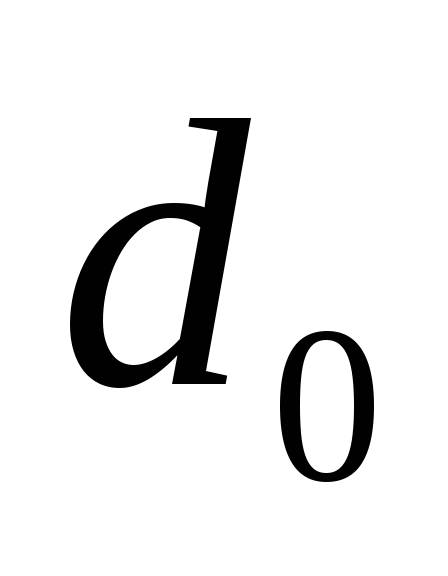
=4,
исправляющие все одиночные и обнаруживающие
все двойные ошибки. Для исправления
всех одиночных ошибок число синдромов
должно бытьn+1
( n
– число разрядов ). Из них n
синдромов используются для указания
местоположения ошибки, а один – нулевой,
соответствует их отсутствию. Следовательно,
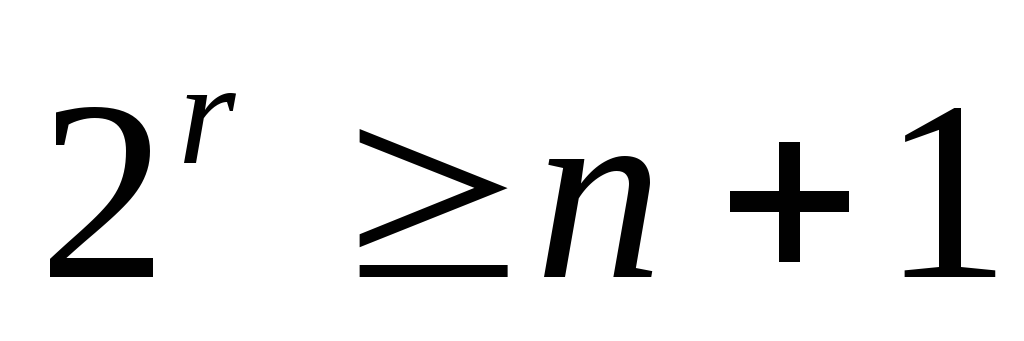
.n=m+k,
где m
–информационные разряды, к –проверочные.
Д 
ля
проверочных разрядов выбираются
комбинации, где присутствует одна «1»,
остальные будут информационными.
Сгруппируем в
первую сумму все элементы, номера которых
имеют значение «1» в 1-м младшем разряде
двоичного числа. Во вторую сумму
сгруппируем элементы, номера которых
имеют значение «1» во втором разряде
двоичного числа и т.д. для третьей и
четвертой сумм.
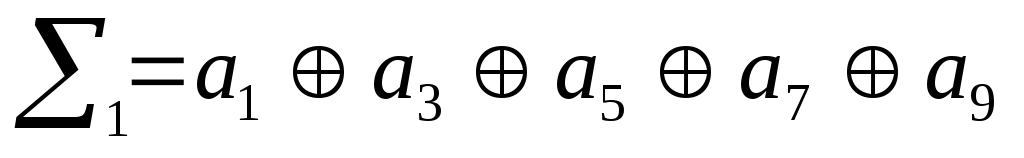
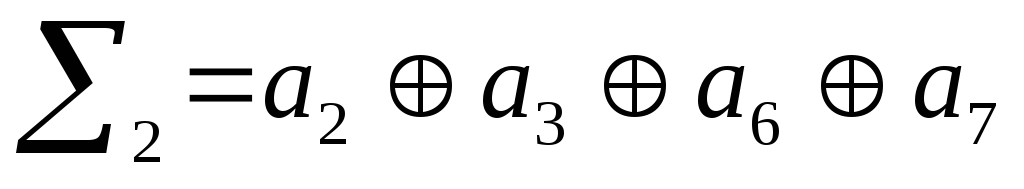
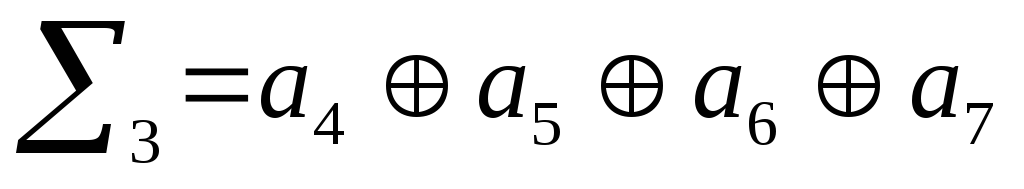
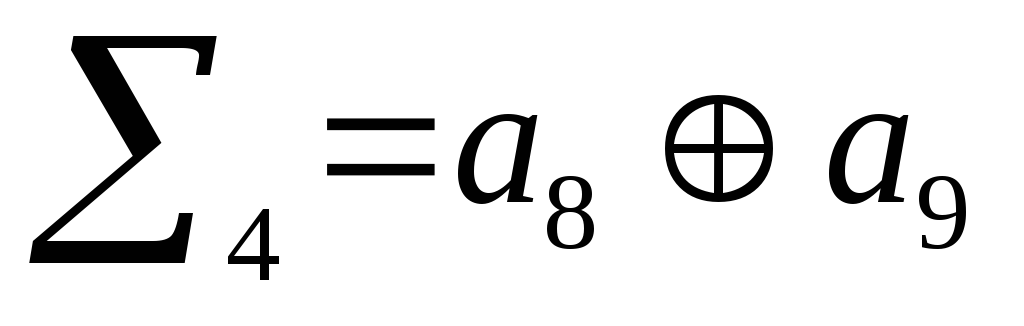
Проверочные биты

входят
только в одну сумму. Такой выбор позволяет
находить ошибочно принятые информационные
элементы и исправлять одиночные ошибки.
Полная кодовая
комбинация передаваемая в линию будет
иметь вид:
Порядок кодирования
кодом Хэмминга в устройстве защиты от
ошибок передатчика:
1. от источника
принимается 5-ти элементная кодовая
комбинация и ее разряды записываются
в отведенных для них местах 3,5,6,7 и 9.
2. Суммированием
по модулю 2 определяются проверочные
разряды. Их значения должны быть такими,
чтобы сумма, в которую входит данный
проверочный разряд, равнялась «0».
Другими словами, каждый проверочный
разряд должен дополнить свою сумму до
четного количества единиц.
3. Полученные
проверочные элементы размещаются на
отведенных для них местах 1,2,4 и 8 в полной
кодовой комбинации.
4. Сформированная
таким образом кодовая комбинация
передается в канал.
Рассмотрим пример:
Источник выдает информационные элементы
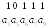
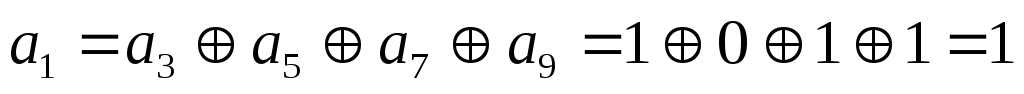
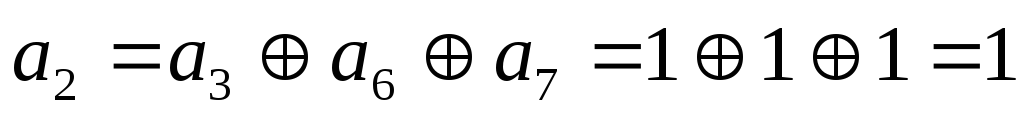
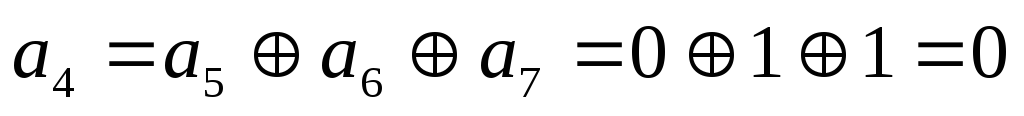
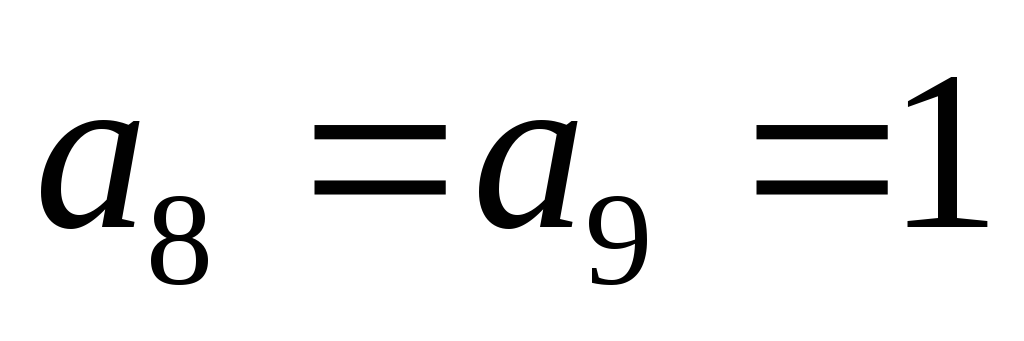
Тогда полная
кодовая комбинация, которая будет
передаваться в канал, имеет вид:
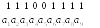
Порядок декодирования
на приеме в устройстве защиты от ошибок.
1. Подсчитываем 4
суммы
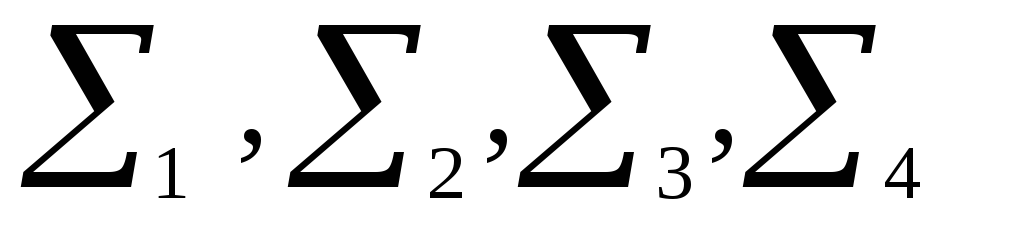
в
каждую из которых входят информационные
разряды и по одному проверочному.
2. Производится
анализ полученных сумм, при этом возможны
три случая:
а) проверочное
число, состоящее из результатов
суммирований равно 0000, что свидетельствует
об отсутствии ошибок.
б) проверочное
число отличается от значения 0000, причем
по его значению можно определить номер
ошибочного разряда.
в) проверочное
число отличается от значения 0000, но
определить место ошибки невозможно.
3. В зависимости
от результатов анализа:
а) информация
выдается потребителю;
б) ошибки исправляются
и информация выдается потребителю;
в) принятая
комбинация стирается и в устройстве
защиты от ошибок вырабатывается сигнал
«ошибка».
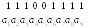
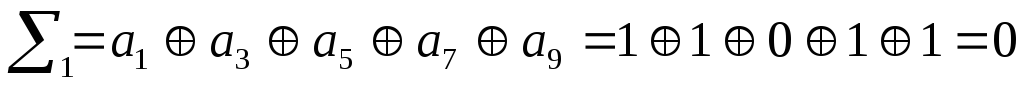
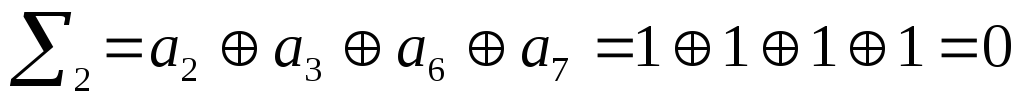
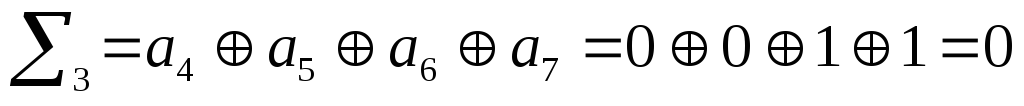
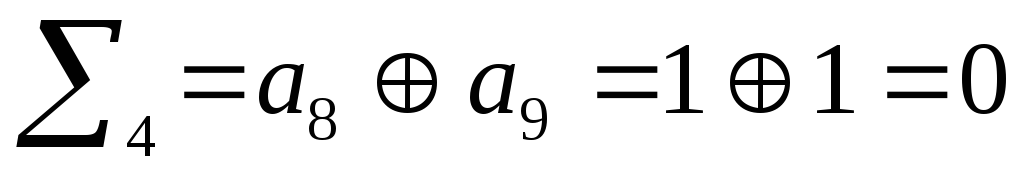
Все «0», значит
комбинация принята верно.
Д 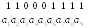
опустим
что произошло искажение в третьем
элементе и вместо 1 принят 0. Тогда
принятая комбинация имеет вид:
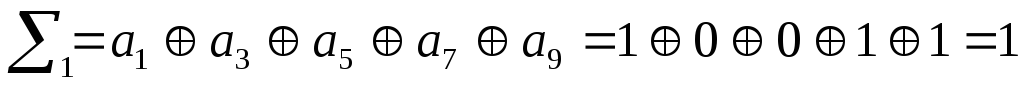
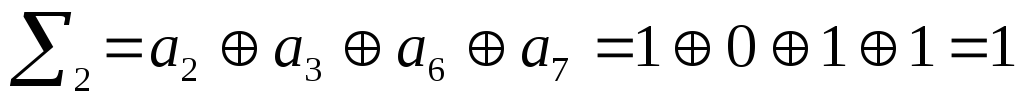

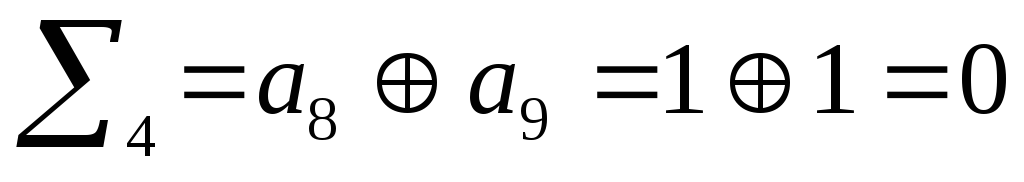
В данном случае
синдром равен 0011, что соответствует
ошибке в 3 элементе кодовой комбинации.
Для устранения данной ошибки необходимо
изменить находящийся в этом элементе
символ на обратный.
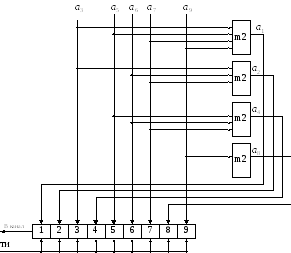
Декодер путем
сложения по модулю 2 от схемы «И» и от
информационного разряда позволяет
исправить ошибку, возникшую в процессе
передачи.

Код Хэмминга имеет
существенный недостаток: при
обнаружении любого числа ошибок он
исправляет лишь одиночные ошибки.
Избыточность семиэлементного кода
Хэмминга равна 0,43. При
увеличении значности кодовых
комбинаций увеличивается число
проверок, но уменьшается избыточность
кода. К тому же код Хэмминга не
позволяет обнаружить групповые ошибки, сконцентрированные
в пакетах. Длина пакета ошибок представляет
собой увеличенную на единицу разность
между именами старшего и младшего
ошибочных элементов.
Соседние файлы в папке Будылдина2
- #
ДКР рисунок Mumarev.vsd
- #
ДКР рисунок.vsd
- #
- #

Код Хэмминга – не цель этой статьи. Я лишь хочу на его примере познакомить вас с самими принципами кодирования. Но здесь не будет строгих определений, математических формулировок и т.д. Эта просто неплохой трамплин для понимания более сложных блочных кодов.
Самый, пожалуй, известный код Хэмминга (7,4). Что значат эти цифры? Вторая – число бит информационного слова — то, что мы хотим передать в целости и сохранности. А первое – размер кодового слова: информация удобренная избыточностью. Кстати термины «информационное слово» и «кодовое слово», употребляются во всех 7-ми книгах по теории помехоустойчивого кодирования, которые мне довелось бегло пролистать.
Такой код исправляет 1 ошибку. И не важно где она возникла. Избыточность несёт в себе 3 бита информации, этого достаточно, чтобы указать на одно из 7 положений ошибки или показать, что её нет. То есть ровно 8 вариантов ответов мы ждём. А 8 = 2^3, вот как всё совпало.
Чтобы получить кодовое слово, нужно информационное слово представить в виде полинома и умножить его на порождающий полином g(x). Любое число, переведя в двоичный вид, можно представить в виде полинома. Это может показаться странным и у не подготовленного читателя сразу встаёт только один вопрос «да зачем же так усложнять?». Уверяю вас, он отпадёт сам собой, когда мы получим первые результаты.
К примеру информационное слово 1010, значение каждого его разряда это коэффициент в полиноме:

Во многих книгах пишут наоборот x+x^3. Не поддавайтесь на провокацию, это вносит только путаницу, ведь в записи числа 2-ичного, 16-ричного, младшие разряды идут справа, и сдвиги мы делаем влево/вправо ориентируясь на это. А теперь давайте умножим этот полином на порождающий полином. Порождающий полином специально для Хэмминга (7,4), встречайте: g(x)=x^3+x+1. Откуда он взялся? Ну пока считайте что он дан человечеству свыше, богами (объясню позже).

Если нужно складывать коэффициенты, то делаем по модулю 2: операция сложения заменяется на логическое исключающее или (XOR), то есть x^4+x^4=0. И в конечном итоге результат перемножения как видите из 4х членов. В двоичном виде это 1001110. Итак, получили кодовое слово, которое будем передавать на сторону по зашумлённому каналу. Замете, что перемножив информационное слово (1010) на порождающий полином (1011) как обычные числа – получим другой результат 1101110. Этого нам не надо, требуется именно «полиномиальное» перемножение. Программная реализация такого умножения очень простая. Нам потребуется 2 операции XOR и 2 сдвига влево (1й из которых на один разряд, второй на два, в соответствии с g(x)=1011):

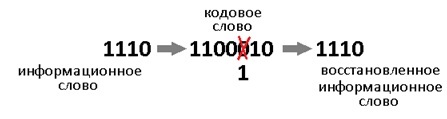
Давайте теперь специально внесём ошибку в полученное кодовое слово. Например в 3-й разряд. Получиться повреждённое слово: 1000110.
Как расшифровать сообщение и исправить ошибку? Разумеется надо «полиномиально» разделить кодовое слово на g(x). Тут я уже не буду писать иксы. Помните что вычитание по модулю 2 — это то же самое что сложение, что в свою очередь, тоже самое что исключающее или. Поехали:

В программной реализации опять же ничего сверх сложного. Делитель (1011) сдвигаем влево до самого конца на 3 разряда. И начинаем удалять (не без помощи XOR) самые левые единицы в делимом (100110), на его младшие разряды даже не смотрим. Делимое поэтапно уменьшается 100110 -> 0011110 -> 0001000 -> 0000011, когда в 4м и левее разрядах не остаётся единиц, мы останавливаемся.
Нацело разделить не получилось, значит у нас есть ошибка (ну конечно же). Результат деления в таком случае нам без надобности. Остаток от деления является синдром, его размер равен размеру избыточности, поэтому мы дописали там ноль. В данном случае содержание синдрома нам никак не помогает найти местоположение повреждения. А жаль. Но если мы возьмём любое другое информационное слово, к примеру 1100. Точно так же перемножим его на g(x), получим 1110100, внесём ошибку в тот же самый разряд 1111100. Разделим на g(x) и получим в остатке тот же самый синдром 011. И я гарантирую вам, что к такому синдрому мы придём в обще для всех кодовых слов с ошибкой в 3-м разряде. Вывод напрашивается сам собой: можно составить таблицу синдромов для всех 7 ошибок, делая каждую из них специально и считая синдром.

В результате собираем список синдромов, и то на какую болезнь он указывает:

Теперь у нас всё есть. Нашли синдром, исправили ошибку, ещё раз поделили в данном случае 1001110 на 1011 и получили в частном наше долгожданное информационное слово 1010. В остатке после исправления уже будет 000. Таблица синдромов имеет право на жизнь в случае маленьких кодов. Но для кодов, исправляющих несколько ошибок – там список синдромов разрастается как чума. Поэтому рассмотрим метод «вылавливания ошибок» не имея на руках таблицы.
Внимательный читатель заметит, что первые 3 синдрома вполне однозначно указывают на положение ошибки. Это касается только тех синдромов, где одна единица. Кол-во единиц в синдроме называют его «весом». Опять вернёмся к злосчастной ошибке в 3м разряде. Там, как вы помните был синдром 011, его вес 2, нам не повезло. Сделаем финт ушами — циклический сдвиг кодового слова вправо. Остаток от деления 0100011 / 1011 будет равен 100, это «хороший синдром», указывает что ошибка во втором разряде. Но поскольку мы сделали один сдвиг, значит и ошибка сдвинулась на 1. Вот собственно и вся хитрость. Даже в случае жуткого невезения, когда ошибка в 6м разряде, вы, обливаясь потом, после 3 мучительных делений, но всё таки находите ошибку – это победа, лишь потому, что вы не использовали таблицу синдромов.
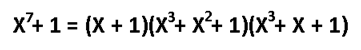
Этот код имеет целых 2 порождающих полинома. Не будет ошибкой использовать любой из них. Для остальных «хэммингов» используйте вот эту таблицу примитивных полиномов:
Соответственно для (15,11) порождающий многочлен g(x)=x^4+x+1. Ну а теперь переходим к десерту – к матрицам. С этого обычно начинают, но мы этим закончим. Для начала преобразую g(x) в матрицу, на которую можно умножить информационное слово, получив кодовое слово. Если g = 1011, то:
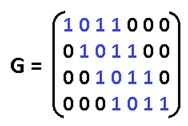
Называют её «порождающей матрицей». Дадим обозначение информационному слову d = 1010, а кодовое обозначим k, тогда:

Это довольно изящная формулировка. По быстродействию ещё быстрее, чем перемножение полиномов. Там нужно было делать сдвиги, а тут уже всё сдвинуто. Вектор d указывает нам: какие строки брать в расчёт. Самая нижняя строка матрицы – нулевая, строки нумеруются снизу вверх. Да, да, всё потому что младшие разряды располагаются справа и от этого никуда не деться. Так как d=1010, то я беру 1ю и 3ю строки, произвожу над ними операцию XOR и вуаля. Но это ещё не всё, приготовьтесь удивляться, существует ещё проверочная матрица H. Теперь перемножением вектора на матрицу мы можем получить синдром и никаких делений полиномов делать не надо.

Посмотрите на проверочную матрицу и на список синдромов, который получили выше. Это ответ на вопрос откуда берётся эта матрица. Здесь я как обычно подпортил кодовое слово в 3м разряде, и получил тот самый синдром. Поскольку сама матрица – это и есть список синдромов, то мы тут же находим положение ошибки. Но в кодах, исправляющие несколько ошибок, такой метод не прокатит. Придётся вылавливать ошибки по методу, описанному выше.
Чтобы лучше понять саму природу исправления ошибок, сгенерируем в обще все 16 кодовых слов, ведь информационное слово состоит всего из 4х бит:

Посмотрите внимательно на кодовые слова, все они, отличаются друг от друга хотя бы на 3 бита. К примеру возьмёте слово 1011000, измените в нём любой бит, скажем первый, получиться 1011010. Вы не найдёте более на него похожего слова, чем 1011000. Как видите для формирования кодового слова не обязательно производить вычисления, достаточно иметь эту таблицу в памяти, если она мала. Показанное различие в 3 бита — называется минимальное «хэммингово расстояние», оно является характеристикой блокового кода, по нему судят сколько ошибок можно исправить, а именно (d-1)/2. В более общем виде код Хэмминга можно записать так (7,4,3). Отмечу только, что Хэммингово расстояние не является разностью между размерами кодового и информационного слов. Код Голея (23,12,7) исправляет 3 ошибки. Код (48, 36, 5) использовался в сотовой связи с временным разделением каналов (стандарт IS-54). Для кодов Рида-Соломона применима та же запись, но это уже недвоичные коды.
Список используемой литературы:
1. М. Вернер. Основы кодирования (Мир программирования) — 2004
2. Р. Морелос-Сарагоса. Искусство помехоустойчивого кодирования (Мир связи) — 2006
3. Р. Блейхут. Теория и практика кодов, контролирующих ошибки — 1986
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали 
, а получили 
. Видно, что эта цепочка больше похожа на исходные
, чем на 
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину 
, равную количеству различающихся цифр в соответствующих разрядах цепочек 
и 
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например, 
, так как все цифры в соответствующих позициях равны, а вот 
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Построение кодов Хэмминга основано на принципе проверки на чётность числа единичных символов: к последовательности добавляется такой элемент, чтобы число единичных символов в получившейся последовательности было чётным:

Знак
здесь означает сложение по модулю 2
:


Если
— то ошибки нет, если
— то однократная ошибка.


Такой код называется
или
. Первое число — количество элементов последовательности, второе — количество информационных символов.


Для каждого числа проверочных символов
существует классический код Хэмминга с маркировкой:

-
то есть —
.


При иных значениях
получается так называемый усечённый код, например международный телеграфный код МТК-2, у которого
. Для него необходим код Хэмминга
который является усечённым от классического




Для примера рассмотрим классический код Хемминга
. Сгруппируем проверочные символы следующим образом:




Получение кодового слова выглядит следующим образом:
-
=
.



На вход декодера поступает кодовое слово
, где штрихом помечены символы, которые могут исказиться в результате действия помехи. В декодере в режиме исправления ошибок строится последовательность синдромов:




называется синдромом последовательности.

Получение синдрома выглядит следующим образом:
-
=
.


Кодовые слова
кода Хэмминга приведены в таблице.
Синдром
указывает на то, что в последовательности нет искажений. Каждому ненулевому синдрому соответствует определённая конфигурация ошибок, которая исправляется на этапе декодирования.

Для кода
в таблице справа указаны ненулевые синдромы и соответствующие им конфигурации ошибок (для вида:
).










- Коды Хемминга — “Все о Hi-Tech”
. all-ht.ru. Дата обращения: 20 января 2016.
Архивировано
15 января 2016 года.
Алгоритм декодирования по Хэммингу абсолютно идентичен алгоритму кодирования. Матрица преобразования соответствующей размерности умножается на матрицу-столбец кодового слова, и каждый элемент полученной матрицы-столбца берётся по модулю 2. Полученная матрица-столбец получила название «матрица синдромов». Легко проверить, что кодовое слово, сформированное в соответствии с алгоритмом, описанным в предыдущем разделе, всегда даёт нулевую матрицу синдромов.
Матрица синдромов становится ненулевой, если в результате ошибки (например, при передаче слова по линии связи с шумами) один из битов исходного слова изменил своё значение. Предположим для примера, что в кодовом слове, полученном в предыдущем разделе, шестой бит изменил своё значение с нуля на единицу (на рисунке обозначено красным цветом). Тогда получим следующую матрицу синдромов.
Заметим, что при однократной ошибке матрица синдромов всегда представляет собой двоичную запись (младший разряд в верхней строке) номера позиции, в которой произошла ошибка. В приведённом примере матрица синдромов (01100) соответствует двоичному числу 00110 или десятичному 6, откуда следует, что ошибка произошла в шестом бите.
Коды, в которых возможно автоматическое исправление ошибок, называются самокорректирующимися. Для построения самокорректирующегося кода, рассчитанного на исправление одиночных ошибок, одного контрольного разряда недостаточно. Как видно из дальнейшего, количество контрольных разрядов
должно быть выбрано так, чтобы удовлетворялось неравенство
или
, где
— количество информационных двоичных разрядов кодового слова. Минимальные значения k при заданных значениях m, найденные в соответствии с этим неравенством, приведены в таблице.



Наибольший интерес представляют двоичные блочные корректирующие коды
. При использовании таких кодов информация передаётся в виде блоков одинаковой длины, и каждый блок кодируется и декодируется независимо от другого. Почти во всех блочных кодах символы можно разделить на информационные и проверочные или контрольные. Таким образом, все слова разделяются на разрешённые (для которых соотношение информационных и проверочных символов возможно) и запрещённые.
Основные характеристики самокорректирующихся кодов:
- Число разрешённых и запрещённых комбинаций. Если
— число символов в блоке,
— число проверочных символов в блоке,
— число информационных символов, то
— число возможных кодовых комбинаций,
— число разрешённых кодовых комбинаций,
— число запрещённых комбинаций. - Избыточность кода. Величину
называют избыточностью корректирующего кода. - Минимальное кодовое расстояние. Минимальным кодовым расстоянием
называется минимальное число искажённых символов, необходимое для перехода одной разрешённой комбинации в другую. - Число обнаруживаемых и исправляемых ошибок. Если
— количество ошибок, которое код способен исправить, то необходимо и достаточно, чтобы
- Корректирующие возможности кодов.









Граница Плоткина
даёт верхнюю границу кодового расстояния:

-
при


Граница Хэмминга
устанавливает максимально возможное число разрешённых кодовых комбинаций:

- где
— число сочетаний из
элементов по
элементам. Отсюда можно получить выражение для оценки числа проверочных символов:



Для значений
разница между границей Хэмминга и границей Плоткина невелика.

Граница Варшамова — Гилберта
для больших n определяет нижнюю границу числа проверочных символов:

Все вышеперечисленные оценки дают представление о верхней границе
при фиксированных
и
или оценку снизу
числа проверочных символов.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова
радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим
! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение 
, мы получим один из кодов, который принадлежит окрестности
радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Код Хэмминга используется:
- в некоторых прикладных программах в области хранения данных;
- при построении дисковых массивов RAID 2
; - в памяти типа ECC
и позволяет «на лету» исправлять однократные и обнаруживать двукратные ошибки.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами 
и 
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
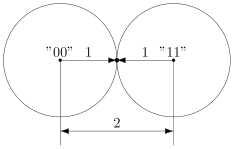
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды 
и 
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
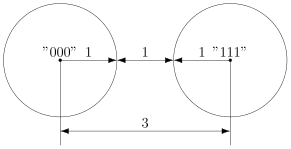
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.

Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием 
будет успешно работать в канале с 
ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает
ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса
других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
Минимальное расстояние 
, а значит 
, откуда получаем, что такой код может исправить до 
ошибок. Обнаруживает же он две ошибки.

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа 
, значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы 
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
- Питерсон У., Уэлдон Э.
Коды, исправляющие ошибки: Пер. с англ. М.: Мир, 1976, 594 c. - Пенин П. Е., Филиппов М. Р.
Радиотехнические системы передачи информации. М.: Радио и Связь, 1984, 256 с. - Блейхут Р.
Теория и практика кодов, контролирующих ошибки. Пер. с англ. М.: Мир, 1986, 576 с.
В середине 1940-х годов в лаборатории Белла
была создана счётная машина Bell Model V
. Это была электромеханическая машина, использующая релейные блоки, скорость которых была очень низка: одна операция за несколько секунд. Данные вводились в машину с помощью перфокарт
с ненадёжными устройствами чтения, поэтому в процессе чтения часто происходили ошибки. В рабочие дни использовались специальные коды, чтобы обнаруживать и исправлять найденные ошибки, при этом оператор узнавал об ошибке по свечению лампочек, исправлял и снова запускал машину. В выходные дни, когда не было операторов, при возникновении ошибки машина автоматически выходила из программы и запускала другую.
Хэмминг часто работал в выходные дни и всё больше раздражался, так как должен был перезагружать свою программу из-за ненадёжности считывателя перфокарт. На протяжении нескольких лет он искал эффективный алгоритм исправления ошибок. В 1950 году
он опубликовал способ кодирования, который известен как код Хэмминга.
Систематические коды образуют большую группу из блочных, разделимых кодов (в которых все символы слова можно разделить на проверочные и информационные). Особенностью систематических кодов является то, что проверочные символы образуются в результате линейных логических операций
над информационными символами. Кроме того, любая разрешенная кодовая комбинация может быть получена в результате линейных операций над набором линейно независимых кодовых комбинаций.
Предположим, что нужно сгенерировать код Хэмминга для некоторого информационного кодового слова. В качестве примера возьмём 15-битовое кодовое слово
хотя алгоритм пригоден для кодовых слов любой длины. В приведённой ниже таблице в первой строке даны номера позиций в кодовом слове, во второй — условное обозначение битов, в третьей — значения битов.

Добавим к таблице 5 строк (по количеству контрольных битов), в которые поместим матрицу преобразования. Каждая строка будет соответствовать одному контрольному биту (нулевой контрольный бит — верхняя строка, четвёртый — нижняя), каждый столбец — одному биту кодируемого слова. В каждом столбце матрицы преобразования поместим двоичный номер этого столбца, причём порядок следования битов будет обратный — младший бит расположим в верхней строке, старший — в нижней. Например, в третьем столбце матрицы будут стоять числа 11000, что соответствует двоичной записи числа три: 00011.
В правой части таблицы оставили пустым один столбец, в который поместим результаты вычислений контрольных битов. Вычисление контрольных битов производим следующим образом: берём одну из строк матрицы преобразования (например,
) и находим её скалярное произведение с кодовым словом, то есть перемножаем соответствующие биты обеих строк и находим сумму произведений. Если сумма получилась больше единицы, находим остаток от его деления на 2. Иными словами, мы подсчитываем, сколько раз в кодовом слове и соответствующей строке матрицы в одинаковых позициях стоят единицы, и берём это число по модулю 2.

Если описывать этот процесс в терминах матричной алгебры, то операция представляет собой перемножение матрицы преобразования на матрицу-столбец кодового слова, в результате чего получается матрица-столбец контрольных разрядов, которые нужно взять по модулю 2.
Например, для строки
:
-
= (1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·0+0·0+1·1+0·0+1·1+0·1+1·1+0·0+1·0+0·0+1·0+0·1) mod 2 = 5 mod 2 = 1.
Полученные контрольные биты вставляем в кодовое слово вместо стоявших там ранее нулей. По аналогии находим проверочные биты в остальных строках. Кодирование по Хэммингу завершено. Полученное кодовое слово — 11110010001011110001.
Поле GF
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов 
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF
. G F — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив 
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Кодирование
Итак, у нас есть система для проверки

Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице 
) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если 
и 
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить 
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF
он тоже работает.

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.
<img src="https://habrastorage.org/getpro/habr/post_images/f26/b2b/c9a/f26b2bc9a9ab9a6d14d51a378653c01f.svg" alt="$ \begin{aligned} x_3=1, x_5=0:\quad x_1=1, x_2=1, x_4=0 \Rightarrow x^{
} = (1, 1, 1, 0, 0),\\ x_3=0, x_5=1:\quad x_1=0, x_2=1, x_4=1 \Rightarrow x^{
} = (0, 1, 0, 1, 1). \end{aligned} $” data-tex=”display”>
Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:
<img src="https://habrastorage.org/getpro/habr/post_images/4de/caf/d26/4decafd26623b55fecc3e410989a2f5d.svg" alt="$ a_1 x^{
}+a_2 x^{
}, $” data-tex=”display”>
где 
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно 
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица 
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. ( Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?
<img src="https://habrastorage.org/getpro/habr/post_images/c65/e4a/4da/c65e4a4da6a38487d63d74f66f7bf647.svg" alt="$ a=01 \to aG=01011 \rightsquigarrow x=01\underline{1}11 \to Hx^T =
^T \neq 0. $” data-tex=”display”>
А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква 
. А может, во втором, и была передана
.
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили 
. Тут у нас есть две возможности: либо это
и было две ошибки (в крайних цифрах), либо это
и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква
. Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква
.
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Коды Хэмминга являются самоконтролирующимися кодами, то есть кодами, позволяющими автоматически обнаруживать ошибки при передаче данных. Для их построения достаточно приписать к каждому слову один добавочный (контрольный) двоичный разряд и выбрать цифру этого разряда так, чтобы общее количество единиц в изображении любого числа было, например, нечётным. Одиночная ошибка в каком-либо разряде передаваемого слова (в том числе, может быть, и в контрольном разряде) изменит чётность общего количества единиц. Счётчики по модулю 2, подсчитывающие количество единиц, которые содержатся среди двоичных цифр числа, дают сигнал о наличии ошибок. При этом невозможно узнать, в какой именно позиции слова произошла ошибка, и, следовательно, нет возможности исправить её. Остаются незамеченными также ошибки, возникающие одновременно в двух, четырёх, и т. д. — в чётном количестве разрядов. Предполагается, что двойные, а тем более многократные ошибки маловероятны.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем
ошибок. Это будет характеристикой канала связи.
Кодирование и декодирование будем обозначать прямой стрелкой ( 
), а передачу по каналу связи — волнистой стрелкой ( 
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения 
и 
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это 
и 
.
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Построение кода Хэмминга
Рассмотрим пример
построения кода Хэмминга, в котором
между видом синдрома и номером ошибочного
разряда имеется однозначное соответствие:
двоичное число синдрома представляет
собой условный номер (в десятичной
системе) того разряда в кодовой
комбинации, где произошла ошибка.
Предположим, что
требуется сформировать код при условии,
что кодовая комбинация содержит 5
информационных символов ( k
=5)
и код должен исправлять однократную
ошибку, т.е. ошибку в одном разряде
( t
И
=1).
Определим требуемое расстояние Хэмминга
и число проверочных разрядов:
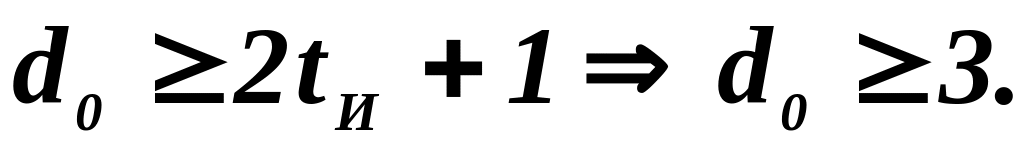
Будем считать, что
d
0
=3.
Найдем число проверочных разрядов:
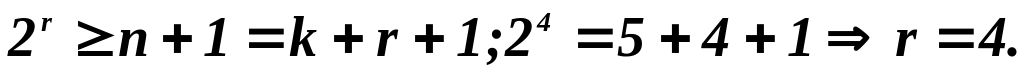
Получили, что для
обеспечения требуемого расстояния
Хэмминга d
0
=3
кодовая комбинация должна содержать 4
проверочных элемента (элементы b
1
b
2
b
3
b
4
),
т.е. код вида (9,5).
Появление единицы
в синдроме происходит следующим
образом:
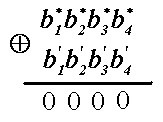
Если синдром имеет
такой вид, то кодовая комбинация не
имеет ошибки ни в одном разряде. Если
синдром имеет вид 0001, то будем считать,
что произошла ошибка в первом разряде
в проверочном элементе b
4
′
.
Синдром вида 0010 свяжем с ошибкой во
втором разряде в проверочном элементе
b
3
′
.
Синдром вида 0100 свяжем с ошибкой в
четвертом разряде в проверочном элементе
b
2
′
(т.к. в
десятичном коде 0100 соответствует числу
4)
.
Синдром
вида 1000 свяжем с ошибкой в восьмом
разряде в проверочном элементе
b
1
′
(т.к. в десятичном коде 1000 соответствует
числу 8)
.
Т.о. одна единица в синдроме соответствует
ошибке в одном из проверочных элементов,
а проверочные элементы будут располагаться
в 1, 2, 4 и 8 разрядах кодовой комбинации.
Запишем вид
синдрома, соответствующий ошибке в
каждом разряде кодовой комбинации в
виде таблицы:
Т.о. всем элементам
кодовой комбинации поставлено в
соответствие значение синдрома, которое
при переводе в десятичный код, соответствует
номеру разряда этого элемента. Таблица
составлена до 15 разряда, т.к. именно это
число позволяет записать двоичная
комбинация из 4-х элементов. Т.к. в примере
кодовая комбинация состоит из 9 элементов
будем пользоваться первыми девятью
строками таблицы.
Построим
алгоритм
оператора R
1
так, чтобы он включал в себя информационные
элементы, ошибка в которых приводила
бы к появлению единицы «1» в младшем
разряде синдрома ( С
4
).
Наличие «1» в младшем разряде С
4
соответствует
проверочному элементу b
4
.
Кроме того, эта «1» есть в синдромах с
номерами 3, 5, 7, 9, 11, 13, 15, что соответствует
информационным элементам а
1
,
а
2
,
a
4
,
a
5
,
a
7
,
а
9
,
a
11
.
Таким образом,
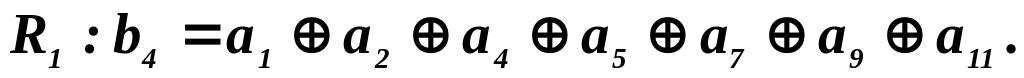
Для девятиразрядной
кодовой комбинации
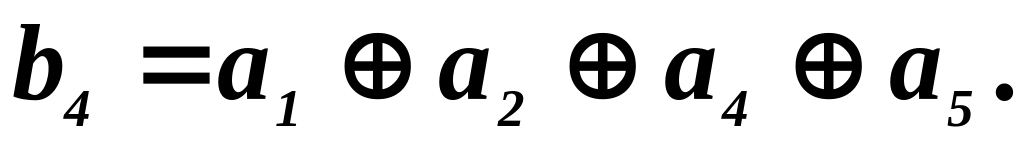
Если в одном из
этих элементов произойдет ошибка, то
это неизбежно приведет к изменению
b
4
.
Для формирования
проверочного элемента b
3
,
в синдроме которого единица стоит
на второй позиции (второй разряд),
отбираем информационные элементы,
имеющие «1» во втором разряде своих
синдромов, т. е. a
1
,
а
3
,
а
4
,
а
6
а
- 7
,
а
10
,
а
- 11
:
Для девятиразрядной
кодовой комбинации
Для формирования
проверочного элемента b
2
,
в синдроме которого единица стоит
на третьей позиции (третий разряд),
отбираем информационные элементы,
имеющие «1» в третьем разряде своих
синдромов, т. е.
a
2
,
а
3
,
а
4
,
а
8
,
а
9
,
а
10
,
а
11
:
Для девятиразрядной
кодовой комбинации
а
а
11 :
кодовой комбинации
Для формирования
проверочного элемента
b
1
,
в синдроме которого единица стоит
на четвертой позиции (четвертый разряд),
отбираем информационные элементы,
имеющие «1» в четвертом разряде своих
синдромов, т. е. a
5
,
а
6
,
а
7
,
а
8
,
а
9
,
а
10
,
а
11
:

Для девятиразрядной
кодовой комбинации

Имеется комбинация
информационных элементов 11001. Для кода
Хэмминга построить разрешенную комбинацию
кода (9,5) и показать, что данный код
исправляет однократную ошибку.
Воспользуемся
проверочной матрицей приведенной выше.
Имеем:
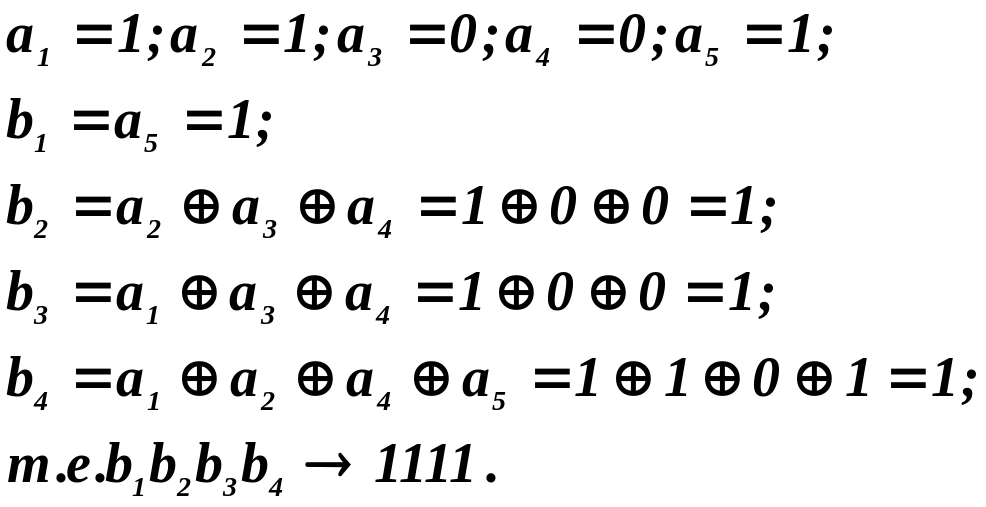
Разрешенная
комбинация имеет вид 11001 1111.
Пусть произошла
ошибка в элементе а
3
,
т. е. приняли комбинацию 11101 1111. Проверим,
исправляется ли ошибка. Для этого
вычислим по информационной части
принятой кодовой комбинации новые
проверочные разряды:
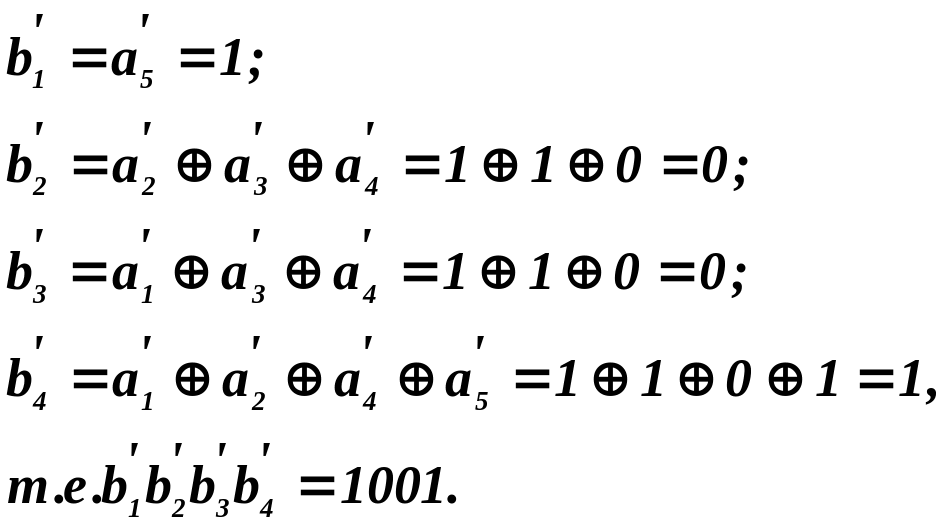
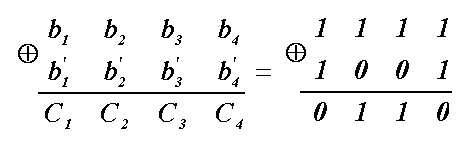
0110
– в десятичной системе есть число 6. На
6-м условном номере согласно таблице
стоит информационный элемент а
3
.
Следовательно, значение принятого
элемента а’
3
нужно исправить: вместо «1» поставить
«0». В результате кодовая комбинация
принята правильно: 11001.
Понятие синдрома
Обнаружение и
исправление ошибок кодом Хэмминга
сводится к определению и последующему
анализу синдрома
.
Синдромом называется
совокупность элементов, которые
получены суммированием по модулю 2
принятых проверочных элементов и
проверочных элементов, вычисленных по
принятым информационным элементам.
Вычисление производится по тому же
правилу, которое применяется для их
определения на передающей стороне.
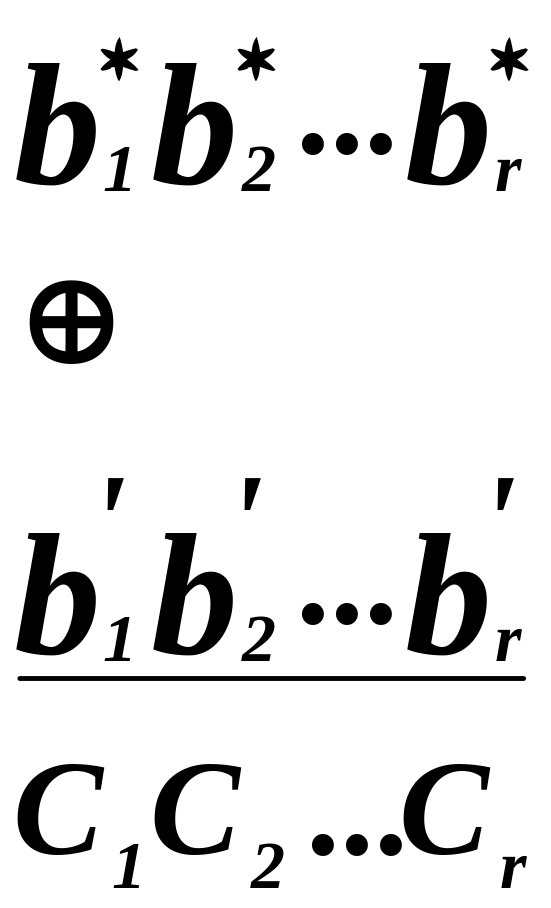
В результате
сложения получается некоторая кодовая
комбинация, которую называют синдромом
или вектором ошибки.
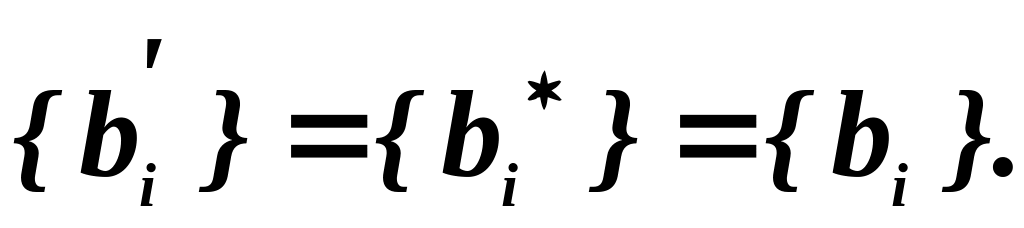
В этом случае все
разряды синдрома будут представлены
нулями:
Если где-то произошла
ошибка, то в составе синдрома появятся
единицы. Это и есть способ обнаружения
ошибок кодом Хэмминга. Поскольку код
Хэмминга имеет минимальное кодовое
расстояние do
=3,
то это означает, что код может исправлять
одну ошибку, т. е. указать номер позиции
в кодовой комбинации, где произошла
ошибка (что для двоичных кодов достаточно,
т.к. в этом случае кодовый элемент на
указанной позиции просто меняется на
противоположный). В одном из вариантов
кода Хэмминга между видом синдрома и
номером ошибочного разряда имеется
однозначное соответствие: двоичное
число синдрома представляет собой
условный номер (в десятичной системе)
того разряда в кодовой комбинации, где
произошла ошибка.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку
из трёх цифр. ( Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF, получаем

В матричном виде эта система будет иметь вид


Транспонирование здесь нужно потому, что
— это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение
, а было отправлено кодовое слово 
. Тогда вектор ошибки по определению

Но в странном мире GF
, где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение
с ошибкой, то 
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.

Вектор ошибки равен 
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Корректирующие коды «на пальцах»

Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.